2. 변수(variable)와 파이썬 자료형(data type) 처리
컴퓨터로 어떠한 일을 수행하려면 데이터를 입력 받아야 한다. 이러한 데이터는 숫자나 문자, 때로는 여러 개의 데이터 조합일 수 있다. 이렇게 입력 받은 데이터는 어딘가에 저장해 놓고 필요한 경우에 읽어 오거나 수정할 수 있어야 한다. 프로그래밍에 있어서 이렇게 데이터를 저장해 놓을 수 있는 공간(메모리의 일정 구역)을 할당하고 특별한 이름을 부여하는 과정을 “변수를 할당한다”라고 한다.
우리가 물건을 인터넷에 시키면 택배기사 아저씨가 정확하게 물건을 배달하여 줄 수 있는 것은 집주소를 물건 주문 시 기록하기 때문이다. 만약 집주소가 중복된다면 어떤 집으로 물건을 배달할지 혼동이 될 것이다. 마찬가지로 변수는 프로그램 내에서 중복된 이름으로 사용할 수 없다. 또한 한번 선언한 변수에는 말 그대로 ‘변하는 값’을 계속 입력할 수 있다. [그림 1]을 살펴 보도록 하자.
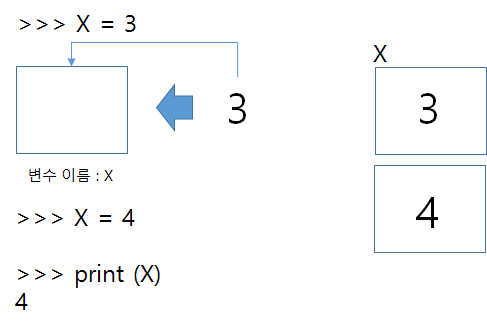 [그림 1] 변수의 생성과 값의 입력
[그림 1] 변수의 생성과 값의 입력
[그림 1]과 같이 파이썬에서 변수를 생성하는 방법은 간단하게 하나의 이름을 지정하면 된다(C등의 프로그래밍언어에서는 변수를 생성하면서 어떤 데이터 형식-숫자, 문자, 문자열 등-을 입력할지 선언해야 하지만 파이썬은 단순하게 이름을 하나 선언하는 것으로 완료된다).
우리는 x라는 변수를 선언하고 ‘=’ 을 기입한 후 3이라는 값을 기입하였다. 여기서 ‘=’를 기준으로 오른쪽에 있는 값을 왼쪽으로 넣어준다는 이야기이다(여기서 ‘=’를 대입연산자라고 한다). 그 후에 다시 ‘X’에 ‘4’를 입력한 후 print() 함수를 사용하여 ‘X’의 값을 출력하면 ‘4’가 출력되는 것을 확인할 수 있다.
앞에서 주문한 물건을 받기 위해서 주소가 같으면 안된다고 이야기하였는데, 또 한가지 주의할 점은 파이썬에서 사용하는 예약어나 함수명을 변수로 사용해서는 안된다는 것이다. 만약 변수명을 print 라고 한다면 파이썬은 화면에 어떤 값을 출력하라는 것인지 아니면 변수로 어떤 값을 보관하고 있어야 하는 것인지 알 수 없기 때문이다.
2.1 숫자형
파이썬에서 사용하는 숫자(Number)형은 숫자의 형태로 이루어진 것으로 초등학교때 배운 정수, 소수 등을 가질 수 있다.
1) 정수(integer)
정수는 양의 정수(1, 2, …), 음의 정수(-1, -2, …) 와 0을 의미한다.
>>> a = 1
>>> a = 0
>>> a = -12) 실수(integer)
실수는 소수점을 포함하는 숫자를 의미한다.
>>> a = 1.1
>>> a = -1.1
>>> a = 1.2E10
>>> a = 1.2E-10
마지막에 표현된 ‘E’의 형태는 컴퓨터에서 사용하는 10의 지수방식을 의미한다 ‘1.2E10’은 1.2 x 10 = 10^10 을, ‘1.2E-10’은 1.2 x 10^-10 을 의미한다.
3) 8진수(octal) 및 16진수(hexadecimal)
8진수와 16진수는 컴퓨터에서 연산을 하기 편리하게 사용하기 위하여 사용하는 표현 방식으로 중학교(?)때 진법 변환을 기억해 보기 바란다. 8진수를 사용하기 위해는 0o(숫자 0, 알파벳 o) 또는 0O(숫자 0, 알파벳 O)를 숫자 앞에 붙여 주면 된다. 16진의 경우에는 0x(숫자 0, 알파벳 x)를 사용한다.
>>> a = 0o17
>>> a = 0x12EF4) 수학 연산자(operator)
수식은 ‘2 + 3’ 과 같이 피 연산자(연산을 당하는 것: 2, 3)와 연산자(연산을 하는 것: +)로 나눌 수 있다. 연산자란 무언가를 계산할 때 어떠한 방식을 하라고 지시하는 것으로 대표적으로 사칙연산자(+, -, *, /)를 생각할 수 있다 – 컴퓨터에서 나누기 표시는 ‘/’를 사용한다-. 단순하게 프롬프트 상에서 다음과 같이 사칙연산을 할 수 있다.
>>> 2 + 3 #덧셈
5
>>> 3 – 2 #뺄셈
1
>>> 2 * 3 #곱셈
6
>>> 2 / 3 #나눗셈
0.6666666666666666
>>> 2 ** 3 #거듭제곱: 2를 3번 곱함
8
>>> 2 % 3 #나머지: 2을 3으로 나누면 몫은 0, 나머지는 2
2
>>> 3 % 2 #나머지: 3을 2로 나누면 몫은 1, 나머지는 1
1
>>> 2 // 3 #나눗셈 후 소수점 이하를 버림: 0.66666 에서 소수점 이하를 버림
0
>>> 3 // 2 #1.5에서 .5를 버림
1
2.2 문자열(String)
파이썬에서 사용하는 문자열은 하나의 문자(character) 또는 문자열(string)을 가질 수 있다.
1) 문자열의 구성
파이썬에서 문자열은 작은 따옴표(‘)의 쌍, 큰 따옴표(“)의 쌍과 큰 따옴표 또는 작은 따옴표 3개의 연속된 쌍으로 만들 수 있다.
>>> a = ‘HELLO’
>>> a = “HELLO”
>>> a = ‘’’HELLO’’’
>>> a = “””HELLO”””
문자열을 만드는데 여러 가지 방식을 만든 이유는 파이썬이 다양한 언어의 문자열을 지원하기 위해서 이다. 영어중에 생략된 글자나 숫자, 또는 소유격을 나타내기 위해서 사용하는 작은따옴표(어퍼스트로피: apostrophe)를 생각해 보면 쉽게 알 수 있다.
>>> a = 'she's gone' #작은따옴표 쌍이 맞지 않는다
SyntaxError: invalid syntax
>>> a = "she's gone" #문자열을 큰 따옴표 쌍으로 만들어 주니 혼동이 없음
>>> print(a)
she's gone
>>> a = "he said that "she is gone"” #큰따옴표의 쌍은 맞으나 문자열을 어떻게 끊어야 하는지 알 수 없음
SyntaxError: invalid syntax
>>> a = 'he said that "she is gone"' #작은 따옴표쌍으로 문자열을 만들고 내부에서 큰따옴표를 사용
>>> print(a)
he said that "she is gone"
>>> a = 'he said that "she's gone"' #작은 따옴표의 쌍이 맞지 않음
SyntaxError: invalid syntax
>>> #문자열 내부에 사용하는 큰 따옴표와 작은 따옴표 앞에 \를 입력하면 인식
>>> a = 'he said that "she\'s gone"'
>>> print(a)
he said that "she's gone"
>>> a = "he said that \"she\'s gone\""
>>> print(a)
he said that "she's gone"
2) 이스케이프(escape) 문자
파이썬뿐만 아니라 여러 프로그래밍 언어는 이스케이프 문자를 지원한다. 이스케이프 문자란 미리 정의해놓은 문자로 특정 기능을 수행한다. 이스케이프 문자는 여러 가지가 있으나 주로 사용하는 것은 다음과 같다.
| 이스케이프 문자 | 기능 | 예제 |
|---|---|---|
| \n | 줄 바꿈 | »> print (“HI\nHELLO”) HI HELLO |
| \t | 탭 | »> print (“HI\nHELLO”) HI HELLO |
| \ | \ 문자 | »> print (“HI\HELLO”) HI\HELLO |
| \’ | ‘ 출력 | |
| \” | “ 출력 |
3) 여러줄의 문자열
변수에 문자열을 입력하다 보면 여러줄의 문자열을 작성할 경우가 있다. 이러한 경우에는 한줄에 문자열을 다 입력하여도 되지만, 가독성이 떨어지게 되므로 다음과 같이 처리할 수 있다(예제를 만들고 보니 참 저렴한 영어다…).
>>> a = "HI\nMY NAME IS MARK\nNICE TO MEET YOU"
>>> print(a)
HI
MY NAME IS MARK
NICE TO MEET YOU
>>> a = '''
HI
MY NAME IS MARK
NICE TO MEET YOU
'''
>>> print(a)
HI
MY NAME IS MARK
NICE TO MEET YOU
>>> a = """
HI
MY NAME IS MARK
NICE TO MEET YOU
"""
>>> print(a)
HI
MY NAME IS MARK
NICE TO MEET YOU
4) 문자열 연산자(operator)
문자열의 경우에는 더하기와 곱하기 연산자를 사용할 수 있다.
>>> "HI" + "HELLO" #두개의 문자열을 붙여서 출력한다
'HIHELLO'
>>> "HI"*3 # 문자열을 3번 반복한다
'HIHIHI'
>>> "*"*10
'**********'
5) 문자열 처리
나중에 조금 복잡한 프로그래밍을 하다 보면 문자열에서 특정한 위치의 문자가 무엇인지 확인하거나 특정 부분의 문자열을 잘라내는 처리를 해야 하는 경우가 있다. 이러한 문자열을 처리하는 방법을 알기 위하여 인덱스(index)라는 개념에 대해 이해를 하여야 한다.
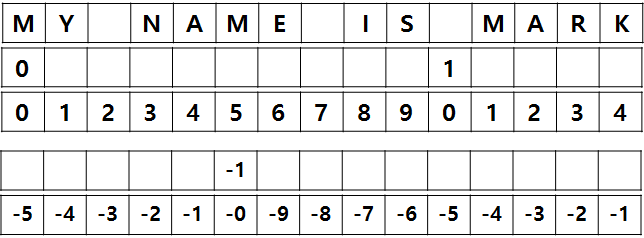 [그림 2] 변수의 생성과 값의 입력
[그림 2] 변수의 생성과 값의 입력
문자열은 0을 시작으로 하는 고유의 길이를 가진다. 위 문장은 총 15개의 문자를 가지고 있으며 각 문자는 고유의 인덱스(index) 번호를 가진다. 즉 ‘I’는 문자열의 8번쨰이며, ‘S’는 문자열의 9번째이다. 음의 인덱스는 문자의 뒤쪽부터 계산되며, 맨 마지막 글자는 ‘-1’의 인덱스를 가진다(실제 문자열의 맨 마지막에는 null 이라는 문자가 하나 더 있기 때문에 그렇다).
>>> a = "MY NAME IS MARK"
>>> a[8]
'I'
>>> a[9]
'S'
>>> a[-7]
'I'
>>> a[-6]
'S'
문자열을 처리하는데 필요한 또 하나의 개념은 슬라이스(slice)이다. 슬라이스는 영어 뜻에서 의미하듯이 하나의 조각을 의미한다. 다음의 예를 확인해 보자.
>>> a[0:2]
'MY'
>>> a[8:10]
'IS'
>>> a[8:9]
'I'
>>> a[11:]
'MARK'
>>> a = "2017-06-25"
>>> year = a[0:4]
>>> month = a[5:7]
>>> day = a[8:]
>>> print(year)
2017
>>> print(month)
06
>>> print(day)
25
슬라이스를 이용하여 특정 문자열을 추출하는 경우에는 변수명[인덱스시작번호:인덱스마지막번호+1]로 처리한다. 만약 인덱스의 마지막을 입력하지 않으면 문자의 마지막을 의미한다.
6) 문자열 포맷팅(formatting)
문자열을 생성하고 출력하는 경우에 단순하게 여러 문자을 합치는 것이 아니라 특정한 값을 포함하고 싶은 경우가 있다. 이런 경우에 사용하는 함수가 format()이다.
>>> age = 20
>>> name = "Mark"
>>> print (name + " is " + str(age) + " years old")
Mark is 20 years old
>>> print ("{0} is {1} years old".format(name, age))
Mark is 20 years old
>>> print("%s is %d years old" % (name, age))
Mark is 20 years old
위의 예에서 ‘%s’와 같은 형식을 포맷팅 코드라고 한다. 파이썬에서 사용하는 포맷팅코드는 다음과 같다. (주의: 포맷팅 코드를 사용하면서 ‘%’를 사용해야 하는 경우에는 ‘%%’로 입력해야 파이썬 인터프리터가 혼동하지 않는다)
| 포맷팅코드 | 설명 |
|---|---|
| %s | 문자열(string): 모든 변수(정수, 실수 등)는 %s를 이용하여 출력할 수 있다 |
| %d | 정수 |
| %c | 문자(character) |
| %f | 실수: ‘%5.7f’와 같은 형식을 사용할 경우에는 정수부분은 5자리(모자라면 공백으로 채운다)로 표시하고 소수점은 7자리까지 표현한다 |
| %o | 8진수 |
| %x | 16진수 |
7) 문자열 관련 함수(function)
파이썬에서는 문자열 처리를 위하여 미리 만들어 놓은 여러 개의 함수가 있다.
a. 특정 문자 개수: count()
>>> a = "My Name is Mark"
>>> a.count('M')
2
>>> a.count('My')
1
b. 문자 길이: len()
>>> a = "My Name is Mark"
>>> len(a)
15
c. 특정 글자의 위치: find()
>>> a = "My Name is Mark"
>>> a.find('i')
8
>>> a.find('I') #대소문자를 구별한다
-1
>>> a.find('M') #가장 먼저 찾은 인덱스를 반환한다
0
>>> a.find('m')
5
>>> a.find('is') #찾은 문자열의 맨 처음 인덱스를 반환한다
8
d. 소문자 -> 대문자: upper()
>>> a = "My Name is Mark"
>>> a.upper()
'MY NAME IS MARK'
e. 대문자 -> 소문자: lower()
>>> a = "My Name is Mark"
>>> a.lower()
'my name is mark'
f. 공백 삭제: lstrip(), rstrip(), strip()
>>> a = " My Name is Mark "
>>> a.lstrip()
'My Name is Mark '
>>> a.rstrip()
' My Name is Mark'
>>> a.strip()
'My Name is Mark'
g. 문자열 치환: replace()
>>> a = "My name is Mark"
>>> a.replace('Mark', 'James')
'My name is James
h. 숫자 -> 문자 변환: str()
>>> a = 10
>>> print(10)
10
>>> print(str(10))
10
>>> age = 20
>>> name = "Mark"
>>> print (name + " is " + age + " years old")
Traceback (most recent call last):
File "<pyshell#45>", line 1, in <module>
print (name + " is " + age + " years old")
TypeError: Can't convert 'int' object to str implicitly
>>> print (name + " is " + str(age) + " years old")
Mark is 20 years old
위에서 age라는 변수를 print() 함수에서 사용하면 오류가 발생한다. 문자열을 구성하기 위하여 ‘+’ 연산자를 사용하였는데 정수형 변수가 나오니 인터프리터는 합산을 해야 하는지 문자열을 결합해야 하는지 확정할 수 없기 때문이다.
i. 문자열 분리: split()
>>> a = "My Name is Mark"
>>> a.split()
['My', 'Name', 'is', 'Mark']
>>> a = "2017-06-25"
>>> a.split('-')
['2017', '06', '25']
split() 함수는 인자를 아무것도 넣어주지 않으면 공백(space)을 기준으로 나누어 주며, 특정 문자를 기준으로 나눌 수 있다. 결과값을 보면 [‘2017’, ‘06’, ‘25’] 과 같이 출력되는데 이러한 형식을 리스트라고 한다. 리스트에 대해서는 다음 절에서 설명하도록 하겠다.
2.3 리스트(list) 자료형
리스트 자료형은 데이터들의 집합을 하나의 변수로 다루기 위하여 사용한다. 리스트는 C나 C++ 언어에서 사용하는 어레이(array)와 비슷한 개념이지만 차이점은 C에서는 동일한 데이터만을 하나의 집합으로 관리할 수 있으나(정수형 어레이는 정수의 값들만으로 구성할 수 있다) 파이썬에서는 다양한 데이터를 하나의 리스트로 관리할 수 있다.
>>> score = [100, 90, 95]
>>> score
[100, 90, 95]
>>> score[0]
100
>>> score[1]
90
>>> score[2]
95
>>> score[3]
Traceback (most recent call last):
File "<pyshell#67>", line 1, in <module>
score[3]
IndexError: list index out of range
리스트는 ‘[‘과 ‘]’의 쌍으로 구성되며, 각각의 요소(element)는 ‘,’를 이용하여 분리한다. 위의 예는 ‘score’라는 변수에 국어, 영어, 수학 점수를 입력한 예이다. 한 사람의 국영수 점수를 위와 같이 리스트로 관리하면 각 과목의 인덱스(위치)만 알고 있으면 하나의 데이터 집합으로 관리할 수 있다. 만약 영희와 철수의 시험점수를 관리하고 싶다면 어떻게 구성하면 가능할까? 다음의 예를 보자
>>> score = [[100, 90, 95], [70, 80, 90]]
>>> score
[[100, 90, 95], [70, 80, 90]]
>>> score[0]
[100, 90, 95]
>>> score[1]
[70, 80, 90]
>>> score[0][0]
100
>>> score[0][1]
90
리스트의 각 요소는 다양한 자료형이 입력될 수 있다고 하였다. 위의 예는 리스트의 요소로 리스트를 가지고 있는 형태로 score[0]를 영희, score[1]을 철수라고 하면 하나의 리스트 변수에 학생의 점수를 전부 관리할 수 있는 편의성을 제공한다.
1) 리스트 관련 함수(function)
파이썬에서 문자열은 작은 따옴표(‘)의 쌍, 큰 따옴표(“)의 쌍과 큰 따옴표 또는 작은 따옴표 3개의 연속된 쌍으로 만들 수 있다.
a. 추가 및 삭제: append(), insert(), pop(), del()
>>> a = [10, 20, 30, 40]
>>> a.append(50)
>>> a
[10, 20, 30, 40, 50]
>>> a.insert(1, 15)
>>> a
[10, 15, 20, 30, 40, 50]
>>> a.pop()
50
>>> a
[10, 15, 20, 30, 40]
>>> a.pop(1)
15
>>> a
[10, 20, 30, 40]
>>> del a[1]
>>> a
[10, 30, 40]
append() 함수는 리스트의 맨 마지막에 데이터를 추가할 수 있으며 insert() 함수는 특정 인덱스에 데이터를 추가할 수 있다. pop()의 경우에는 인자를 전달하지 않으면 맨 마지막 값을 삭제하고, 인덱스 값을 인자로 전달하면 해당 인덱스의 값을 삭제한다.
b. 값의 변환
>>> a = [10, 20, 30, 40]
>>> a[1]
20
>>> a[1] = 25
>>> a
[10, 25, 30, 40]
특정 인덱스의 값을 대입연산자(=)를 이용하여 변경할 수 있다.
c. 개수: count()
>>> a = ['A+', 'A0', 'A+', 'F']
>>> a.count('A+')
2
>>> a.count('F')
1
>>> a.count('B+')
0
d. 정렬: sort()
>>> a = ['A+', 'A0', 'A+', 'F']
>>> a.sort()
>>> a
['A+', 'A+', 'A0', 'F']
e. 뒤집기: reverse()
>>> a = [30, 20, 40, 15]
>>> a.reverse()
>>> a
[15, 40, 20, 30]
reverse() 함수는 단순하게 리스트의 인덱스를 역순으로 만들어주는 역할을 하며, 내부적으로 정렬을 수행하지는 않는다.
f. 삭제 및 생성: clear(), list()
>>> a = ['A+', 'A0', 'A+', 'F']
>>> a.clear()
[]
>>> type(a)
<class 'list'>
>>> b = list()
>>> type(b)
<class 'list'>
type() 함수는 변수의 자료형을 반환하는 함수이다. 초기에 빈 리스트를 생성하기 위해서는 list() 함수를 사용할 수 있다.
2) 리스트 연산자(operator)
리스트 연산자는 문자열과 같이 ‘+’와 ‘*’ 연산자를 사용할 수 있다.
>>> a = [10, 20, 30]
>>> b = [40, 50]
>>> a+b
[10, 20, 30, 40, 50]
>>> a*2
[10, 20, 30, 10, 20, 30]
2.4 튜플(tuple) 자료형
튜플형은 리스트와 비슷하지만 내부에 있는 데이터를 삭제하거나 추가할 수 없는 상수와 같은 개념으로 사용한다.
>>> a = (10, 20, 30)
>>> a
(10, 20, 30)
>>> a.append(40)
Traceback (most recent call last):
File "<pyshell#130>", line 1, in <module>
a.append(40)
AttributeError: 'tuple' object has no attribute 'append'
>>> a[1] = 25
Traceback (most recent call last):
File "<pyshell#141>", line 1, in <module>
a[1] = 25
TypeError: 'tuple' object does not support item assignment
>>> del a(1)
SyntaxError: can't delete function call
>>> a[1]
20
>>> a[1:]
(20, 30)
2.5 딕셔너리(Dictionary) 자료형
리스트나 튜플의 경우에는 데이터의 값을 가지고 오기 위하여 인덱스(index)를 이용하였다. 그러나 이러한 경우에는 인덱스 번호에 어떤 데이터를 저장하였는지 정확하게 알 수 있어야 하며, 프로그램에서 데이터의 가독성이 떨어지는 문제점을 가진다.
이러한 부분을 해결하기 위하여 도입된 딕셔너리(사전) 자료형은 키(key)와 값(value)의 쌍을 가진다.
>>> score = {'korean':100, 'english':90, 'math':95}
>>> score
{'math': 95, 'korean': 100, 'english': 90}
>>> score['english']
90
>>> score['english'] = 95
>>> score
{'math': 95, 'korean': 100, 'english': 95}
>>> score['science'] = 90
>>> score
{'math': 95, 'korean': 100, 'science': 90, 'english': 95}
>>> del score['math']
>>> score
{'korean': 100, 'science': 90, 'english': 95}
>>> del score['music']
Traceback (most recent call last):
File "<pyshell#159>", line 1, in <module>
del score['music']
KeyError: ‘music'
딕셔너리형은 인덱스 대신 위의 예와 같이 키값을 이용하여 데이터값을 조회할 수 있는 장점을 가진다. 리스트에서는 입력한 순서대로 데이터가 유지되나 딕셔너리형에서는 파이썬에서 자체적으로 순서를 정렬하는 차이점을 가지고 있다. 주의할점은 키값은 고유값으로 중복될 수 없는 값이다. 만약 키값이 중복된다면 파이썬에서는 어떤 데이터를 반환할지 결정할 수 없기 때문이다.
딕셔너리의 키값이 존재하는 경우에는 해당 키값의 데이터를 변경하게 되고, 키값이 없는 경우에는 새로운 쌍을 추가한다. 딕셔너리의 키값을 지정하여 데이터를 삭제할 수 있으며, 키값이 존재하지 않는 경우에는 삭제시에 오류를 발생한다.
1) 딕셔너리 함수(fuction)
딕셔너리를 처리하기 위한 함수는 다음과 같다.
a. Key 객체 반환: keys()
>>> score = {'korean':100, 'english':90, 'math':95}
>>> score.keys()
dict_keys(['math', 'korean', 'english'])
>> list(score.keys())
['math', 'korean', 'english']
keys() 함수는 딕셔너리의 키값들의 객체(object)를 반환한다. 파이썬 2.X 버전에서는 리스트를 반환하였으나 메모리 낭비를 없애기 위하여 객체형으로 반환을 하는 것으로 변경되었다. 리스트형으로 반환한다. append()등의 함수를 사용하기 위해서는 list() 함수를 이용하여 데이터를 변환할 수 있다.
b. Value 객체 반환: values()
>>> score = {'korean':100, 'english':90, 'math':95}
>>> score.values()
dict_values([95, 100, 90])
>>> list(score.values())
[95, 100, 90]
c. Key, Value 쌍 객체 반환: items()
>>> score = {'korean':100, 'english':90, 'math':95}
>>> score.items()
dict_items([('math', 95), ('korean', 100), ('english', 90)])
>>> list(score.items())
[('math', 95), ('korean', 100), ('english', 90)]
d. 삭제: clear()
>>> score = {'korean':100, 'english':90, 'math':95}
>>> score.clear()
>>> score
{}
e. 데이터 가져오기: get()
>>> score = {'korean':100, 'english':90, 'math':95}
>>> score.get('korean')
100
>>> score['korean']
100
>>> score.get('science')
>>>
>>> score.get('science', 'NONE')
'NONE'
get() 함수는 score[‘key값’]과 동일한 기능을 한다. score[‘key값’]의 경우에는 키가 없을 경우 오류가 발생하지만 get()함수는 아무런 값도 반환하지 않는다. 또한 키값이 없는 경우에는 특정한 값을 반환하도록 인자를 추가할 수 있다.
f. 키값 유무 확인: in
>>> score = {'korean':100, 'english':90, 'math':95}
>>> 'korean' in score
True
>>> 'science' in score
False
앞서서 키값이 없는 값을 조회하는 경우에는 오류를 발생한는 것을 확인하였다. 이러한 것을 막기 위하여 딕셔너리 내부에 키값이 존재하는지 확인하기 위해 ‘in’을 사용한다. ‘True’는 ‘참’을 의미하며, ‘False’는 거짓을 의미한다.
2.6 집합(set) 자료형
집합 자료형은 기존의 프로그래밍언어에서는 보기 힘들었던 자료형으로 데이터를 집합으로 취급하여 집합연산(교집합, 합집합 등)을 할 수 있는 장점이 있다. 집합 자료형은 순서가 없이 존재하기 때문에 리스트나 튜플의 인덱스를 이용하여 데이터를 조회하거나 딕셔너리의 키값을 이용하는 방법이 불가능하기 때문에 리스트나 튜플로 변경하여 사용하여야 한다.
>>> a = set([10, 20, 30])
>>> a
{10, 20, 30}
>>> b = set("PYTHON")
>>> b
{'P', 'T', 'O', 'H', 'Y', 'N'}
집합 자료형은 리스트 또는 문자열을 데이터로 입력받아 키값이 없는 딕셔너리 형태의 데이터를 반환한다. 또한 집합 자료형은 순서가 없이 존재하기 때문에 리스트나 튜플의 인덱스를 이용하여 데이터를 조회하거나 딕셔너리의 키값을 이용하는 방법이 불가능하기 때문에 리스트나 튜플로 변경하여 사용하여야 한다.
1) 집합 연산
집합 자료형은 수학시간에 배운 교집합, 합집합, 차집합 연산을 할 수 있다.
a. 교집합(intersection)
>>> a = set([10, 20, 30])
>>> b = set([30, 40, 50])
>>> a & b
{30}
>>> a.intersection(b)
{30}
b. 합집합(union)
>>> a = set([10, 20, 30])
>>> b = set([30, 40, 50])
>>> a | b
{50, 20, 40, 10, 30}
>>> a.union(b)
{50, 20, 40, 10, 30}
합집합은 중복된 값은 하나만 반환한다.
c. 차집합(difference)
>>> a = set([10, 20, 30])
>>> b = set([30, 40, 50])
>>> a - b
{10, 20}
>>> a.difference(b)
{10, 20}
2) 집합 함수(function)
집합 자료형은 데이터를 조작하기 위하여 다양한 함수를 제공한다.
a. 값 추가하기: add(), update()
a = set([10, 20, 30])
>>> a
{10, 20, 30}
>>> a.add(40)
>>> a
{40, 10, 20, 30}
>>> a.update([50, 60, 70])
>>> a
{70, 40, 10, 50, 20, 60, 30}
b. 값 삭제: remove()
>>> a = set([10, 20, 30])
>>> a
{10, 20, 30}
>>> a.remove(20)
>>> a
{10, 30}
2.7 참(True)/거짓(False) 자료형
참과 거짓은 특정 변수에 값이 비어 있거나 조건 비교를 하기 위하여 사용한다.
| 값 | True or False |
|---|---|
| “abc” | True |
| “” | False |
| [10, 20, 30] | True |
| [] | False |
| 1 | True |
| 0 | False |
| None | False (파이썬에는 None 이라는 데이터 값이 존재한다. 단순하게 값이 없다고 생각하면 된다) |
활용 방법은 다음장의 흐름제어 부분에서 설명하도록 한다.