11. 일반적인 웹 페이지 크롤링
우리는 앞절에서 다양한 API를 이용하여 서비스 업체에서 제공하는 데이터를 수집하였다. 과거의 고전적인 웹 클롤링은 서비스업체에서 제공해주는 API를 사용하는 것이 아니라 웹 페이지에 직접 방문하여 HTML 파일을 읽어오고 이를 분석하여 필요한 데이터를 추출, 정보로 가공하였다. 그러나 웹 서비스되는 컨텐츠들은 해당 서비스업체의 자산으로 분류될 수 있으며, 이를 동의없이 가가져오는 것 심각한 저작권 문제를 가질 수 있다.
일반적인 저작권법에 의하면 단순 링크(사이트 대표 주소의 링크) 및 직접 링크(특정 게시물을 링크)하는 것에 대해서는 허용하고 있으나, 저작물의 일부를 홈페이지에 프레임을 이용하여 표시(프레임 링크)하거나 저작물 전체를 홈페이지에 표시(임베드 링크)하는 것에 대해서는 위반으로 판단하고 있다. 또한 웹 사이트에 로봇(크롤러)이 접근하는 것을 방지하기 위한 규약을 웹 페이지 루트(root)에 ‘robots.txt’ 파일로 지정할 수 있다. 다음은 ‘robots.txt’ 파일을 작성하는 예이다.
| Site | Status |
|---|---|
| 모두 허용 | User-agent:* Allow: / |
| 모두 차단 | User-agent:* Disallow: / |
| 다른 예 | User-agent: googlebot #googlebot만 허용 Disallow: /bbs/ # /bbs 데렉터리 접근 차단 |
저작권에 대한 부분은 각자의 몫으로 남겨두고 이번장에서는 일반적인 웹 서비스의 데이터를 처리하기 위하여 이상한 나라의 엘리스에 나오는 ‘Beautiful Soup, so rich and green,…’에 나오는 맛있는(?) 스프와 이름이 같은 ‘BeautifulSoup’을 이용하는 방법에 대해 알아보고, 국내 프렌차이즈 닭집 가맹점 주소를 가지고 오는 방법을 알아보도록 하겠다.
11.1 이상한 나라의 엘리스 맛있는 스프: BeautifulSoup
‘BeautifulSoup’ 패키지는 파이썬에서 제공해주는 HTML 파싱(parsing) 라이브러리로써 웹의 태그나 클래스의 값을 손쉽게 가져올 수 있도록 지원한다. Beautiful Soup 3.x 버전까지는 파이썬 2.x 버전만을 지원하였으나 새로운 bs4 파서를 통하여 파이썬 3.x 버전을 지원하게 되었다. ‘BeautifulSoup’의 기능적인 특징은 다음과 같다.
1) 단순한 몇 개의 메소드를 가지고 웹페이지의 내용을 검색하거나 필요한 태그, 클래스등에서 데이터를 추출할 수 있다
2) HTML 문서 뿐만이 아니라 XML 형식의 데이터도 읽고, 분석할 수 있다
3) 다국어 지원을 위하여 Encoding 형식을 지정할 수 있다(이 부분은 한국어 홈페이지의 데이터를 분석하는데 상당히 중요하다. 요즘은 기본적으로 ‘UTF-8’ 형식을 사용하지만, ‘CP949’ 형식의 홈페이지도 상당수 존재한다)
설치는 단순하게 pip를 이용하여 이루어진다. 우리는 파이썬 3.x 버전을 사용하고 있으므로 ‘beautifulsoup4’를 설치한다.
[파이썬이 설치된 경로]\\pip install beautifulsoup4
이제 예제를 좀더 간단하게 하기 위하여 연습용 html을 만들고 각 태그의 값을 조회하기 위하여파이썬 쉘을 수행하고 다음의 예를 실행하여 보자
1) Tag 및 Tag Name 조회
>>> from bs4 import BeautifulSoup
>>> html = '<td class="title"><div class="tit3"><a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a></div></td>'
>>> soup = BeatifulSoup(html, 'html.parser')
>>> soup
<td class="title"><div class="tit3"><a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a></div></td>
>>> tag = soup.td
>>> tag
<td class="title"><div class="tit3"><a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a></div></td>
>>> tag = soup.div
>>> tag
<div class="tit3"><a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a></div>
>>> tag = soup.a
>>> tag
<a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a>
>>> tag.name
'a'
위의 예제에서 손쉽게 태그명을 가지고 해당 데이터를 가지고 올 수 있으며, 해당 데이터는 각 Name을 가지고 있는 것이 확인된다.
2) 속성(Attribute) 값
>>> tag = soup.td
>>> tag['class']
['title']
>>> tag = soup.div
>>> tag['class']
['tit3']
>>> >>> tag.attrs
{'class': ['tit3']}
각 태그의 속성값은 ‘class’값을 가지고 있으며, 속성값을 이용하여 데이터를 조회할 수 있다. 또한 내가 지금 가지고 있는 데이터의 속성(attr)이 어떤 것인지 확인할 수 있다.
3) 속성 (Attribute) 조회
‘BeautifulSoup’은 태그 속성값을 이용하여 데이터 조회를 할 수 있다.
>>> tag = soup.find('td', attrs={'class':'title'})
>>> tag
<td class="title"><div class="tit3"><a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a></div></td>
>>> tag = soup.find('div', attrs={'class':'tit3'})
>>> tag
<div class="tit3"><a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a></div>
이 부분은 우리가 목적으로 하는 HTML을 파싱하는데 상당히 중요한 부분으로 만약 모든 <td> 태그 내의 데이터를 가지고 오고 원하는 데이터만을 찾기는 상당히 어렵다. 잘 만든 홈페이지라면 각 태그의 ‘class’ 명등을 가지고 있고, 이를 이용하여 데이터를 편하게 조회할 수 있다. 복수개의 데이터를 조회하기 위해서는 ‘find()’ 대신 ‘findAll()’을 사용하면 된다.
이제 본격적으로 HTML에서 데이터를 가지고 오기 위하여 다음과 같이 코드를 작성해 본다.
>>> import urllib.request
>>> from bs4 import BeautifulSoup
>>> html = urllib.request.urlopen('http://movie.naver.com/movie/sdb/rank/rmovie.nhn')
>>> soup = BeautifulSoup(html, 'html.parser')
>>> print(soup.prettify())
<!DOCTYPE html>
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<meta content="IE=edge" http-equiv="X-UA-Compatible">
<meta content="http://imgmovie.naver.com/today/naverme/naverme_profile.jpg" property="me2:image"/>
<meta content="네이버영화 " property="me2:post_tag"/>
<meta content="네이버영화" property="me2:category1"/>
....(이하 중략)
<!-- //Footer -->
</div>
</body>
</html>
본 예제에서는 네이버 영화의 랭킹(‘http://movie.naver.com/movie/sdb/rank/rmovie.nhn’) 사이트를 urllib.urlopen() 메소드를 이용하여 읽어온 후 ‘BeautifulSoup’ 객체를 ‘html.parser’ 기본 객체를 이용하여 생성하였다. ‘soup.prettify()’ 메소드를 이용하면 ‘BeautifulSoup’ 객체를 들여쓰기(indent)한 상태로 확인할 수 있다. 실제 호출한 홈페이지는 [그림 1]과 같은 형태를 가진다.
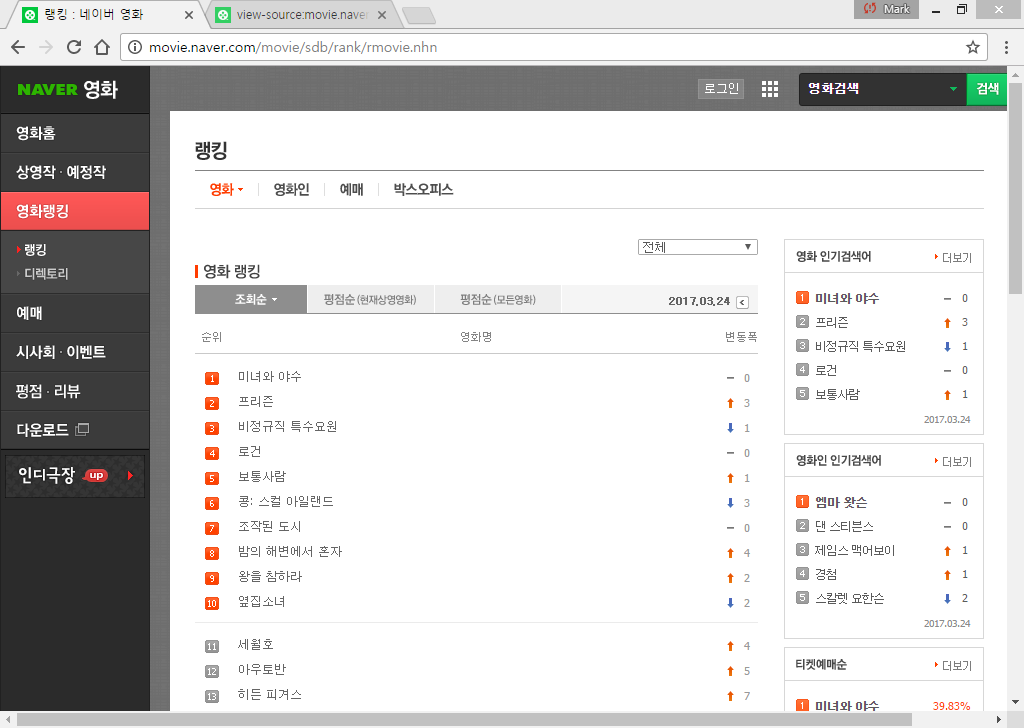 [그림 1] 네이버 영화 랭킹 페이지
[그림 1] 네이버 영화 랭킹 페이지
우리가 자료로 가지고 오고 싶은 데이터는 영화제목이므로 HTML이 어떻게 구성되어있는지 확인하기 위하여 브라우저의 소스보기 기능을 이용하면 [그림 2]와 같이 구성되어 있는 것을 확인할 수 있다.
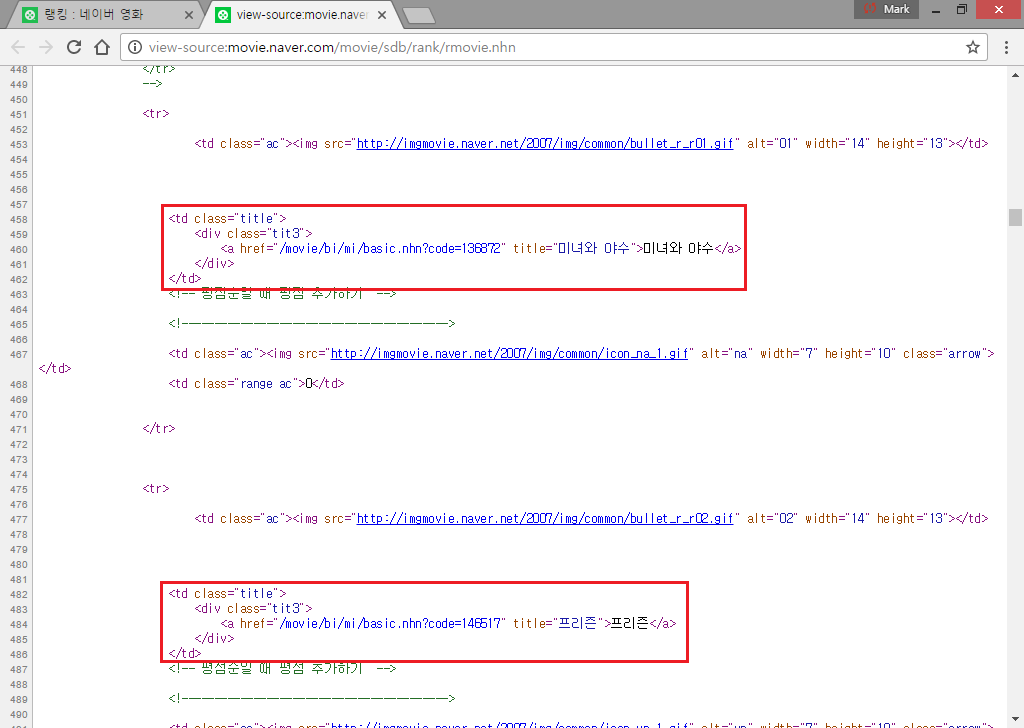 [그림 2] 네이버 영화 랭킹 HTML 구조
[그림 2] 네이버 영화 랭킹 HTML 구조
HTML의 형식을 확인해 보니 영화제목은 ‘<td>’쌍 안에 ‘<div>쌍을 가지고 있으며, 그 내부에 ‘a’ 태그로 구성되어 있음이 확인된다(실제 앞에서 사용한 예제다). 먼저 ‘<div>’ 태그의 속성이 class=’tit3’인 값들을 페이지에서 모두 찾아보자.
>>> import urllib.request
>>> from bs4 import BeautifulSoup
>>> html = urllib.request.urlopen('http://movie.naver.com/movie/sdb/rank/rmovie.nhn')
>>> soup = BeautifulSoup(html, 'html.parser')
tags = soup.findAll('div', attrs={'class':'tit3'})
>>> tags
[<div class="tit3">
<a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a>
</div>, <div class="tit3">
<a href="/movie/bi/mi/basic.nhn?code=146517" title="프리즌">프리즌</a>
</div>, <div class="tit3">
<a href="/movie/bi/mi/basic.nhn?code=152161" title="비정규직 특수요원">비정규직 특수요원</a>
</div>, <div class="tit3">
<a href="/movie/bi/mi/basic.nhn?code=117787" title="로건">로건</a>
… (이하 중략)
</div>, <div class="tit3">
<a href="/movie/bi/mi/basic.nhn?code=17796" title="일 포스티노">일 포스티노</a>
</div>]
>>>
실제 HTML내의 데이터와 확인을 해보면 총 50개의 랭크 데이터를 가지고 온 것을 확인할 수 있다. 이제 우리가 원하는 것은 제목만을 추출하는 것이므로 다음과 같이 작성한다.
>>> for tag in tags:
print(tag.a)
<a href="/movie/bi/mi/basic.nhn?code=136872" title="미녀와 야수">미녀와 야수</a>
<a href="/movie/bi/mi/basic.nhn?code=146517" title="프리즌">프리즌</a>
… (이하 중략)
<a href="/movie/bi/mi/basic.nhn?code=143499" title="콜로설">콜로설</a>
<a href="/movie/bi/mi/basic.nhn?code=17796" title="일 포스티노">일 포스티노</a>
>> for tag in tags:
print(tag.a.text)
미녀와 야수
프리즌
… (이하 중략)
콜로설
일 포스티노
>>> for tag in tags:
tag.a['title']
'미녀와 야수'
'프리즌'
… (이하 중략)
'콜로설'
'일 포스티노'
우리는 수집한 ‘<div>’ 태그 내에서 ‘a’ 태그에 대한 값을 확인하였고, ‘a’ 태그 내에 있는 텍스트를 ‘.text’ 속성을 이용하여 손쉽게 네이버 영화 랭킹 50개의 제목을 추출하였다. 또한 ‘a’ 태그 내의 ‘title’ 속성에도 제목을 포함하고 있으므로 tag.a[‘title’] 과 같은 방식으로도 제목의 추출이 가능하다.