8. 네이버(NAVER) 데이터 수집하기
네이버의 서비스는 ‘네이버 아이디로 로그인’ 이라는 서버 인증을 통해 Access Token을 가지고온후 API를 사용할 수 있는 서비스와, HTTP 헤더에 클라이언트 아이디와 시크릿(secret) 값만을 얹어 전송하면 되는 비로그인 서비스로 나뉜다. 네이버의 뉴스, 블로그 및 까페의 글들은 로그인을 하지 않고 비로그인 방식으로 데이터를 조회하여 가지고 올 수 있도록 설계되어 있어 복잡한 인증 과정을 거치지 않아도 되고 어플리케이션을 만들 경우 Access Token을 얻기 위한 웹 페이지 처리를 하지 않아도 되는 장점이 있다. 그러나 2가지 제약 사항을 가진다.
1) 하루 검색 기사수: API 호출이 25,000회/일로 제한되어 있다. 최대 한번 호출에 100개의 검색을 가지고 올 수 있으므로 250,000건의 데이터를 가지고 올 수 있다.
2) 검색 포인터 문제: 본 책을 쓰고 있는 시점에 가장 검색 이슈가 되는 부분은 대통령 탄핵(언제 책이 출간될지 모르겠지만..) 부분이였다. 실제 네이버에서 “탄핵”이라는 데이터를 검색하면 뉴스에서만 약 43만건의 데이터가 검색되는데 최대 1,000개밖에 API를 이용하여 가지고 올 수 없다(코드에서 자세히 설명하겠다)
물론 상업적으로 네이버의 기사를 크롤링한다면, 계약을 통하여 제약 사항을 해결할 수 있으리라 생각이 들지만 2)번 사항에 대해서는 조금 가혹하다는 생각이 든다.
8.1 검색 API의 활용
뉴스, 블로그 및 까페의 글들을 수집하기 위하여 다음의 코드를 작성한다.(코드를 작성하기 전에 먼저 네이버에 계발자 계정을 가지고 있어야 한다. 개발자 계정을 만드는 방법은 3. 네이버(Naver) API 사용하기 를 참조하기 바란다)
import os
import sys
import urllib.request
import datetime
import time
import json
from config import *
#[CODE 1]
def get_request_url(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", app_id)
req.add_header("X-Naver-Client-Secret", "scxKeSJYib")
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print ("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
#[CODE 2]
def getNaverSearchResult(sNode, search_text, page_start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % sNode
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(search_text), page_start, display)
url = base + node + parameters
retData = get_request_url(url)
if (retData == None):
return None
else:
return json.loads(retData)
#[CODE 3]
def getPostData(post, jsonResult):
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
#Tue, 14 Feb 2017 18:46:00 +0900
pDate = datetime.datetime.strptime(post['pubDate'], '%a, %d %b %Y %H:%M:%S +0900')
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S')
jsonResult.append({'title':title, 'description': description,
'org_link':org_link, 'link': org_link,
'pDate':pDate})
return
def main():
jsonResult = []
# 'news', 'blog', 'cafearticle'
sNode = 'news'
search_text = '탄핵'
display_count = 100
jsonSearch = getNaverSearchResult(sNode, search_text, 1, display_count)
while ((jsonSearch != None) and (jsonSearch['display'] != 0)):
for post in jsonSearch['items']:
getPostData(post, jsonResult)
nStart = jsonSearch['start'] + jsonSearch['display']
jsonSearch = getNaverSearchResult(sNode, search_text, nStart, display_count)
with open('%s_naver_%s.json' % (search_text, sNode), 'w', encoding='utf8') as outfile:
retJson = json.dumps(jsonResult,
indent=4, sort_keys=True,
ensure_ascii=False)
outfile.write(retJson)
print ('%s_naver_%s.json SAVED' % (search_text, sNode))
if __name__ == '__main__':
main()
코드를 수행하여 저장한 json 데이터를 열어보면 [그림 1]과 같다.
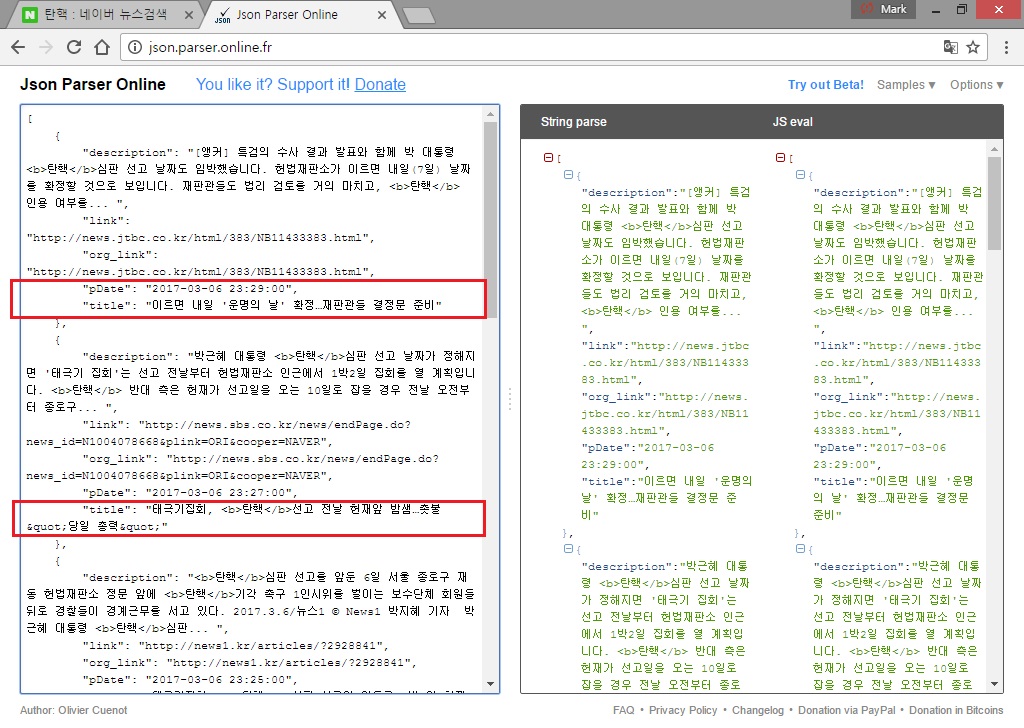 [그림 1] 뉴스에서 수집된 JSON 데이터
[그림 1] 뉴스에서 수집된 JSON 데이터
실제 네이버에서 동일한 ‘탄핵’ 이라는 데이터를 검색한 화면을 보면 [그림 2]와 같다.
 [그림 2] 네이버 페이지 검색 결과
[그림 2] 네이버 페이지 검색 결과
[그림 1]의 사각형으로 표시된 기사 내용이 [그림 2]의 처음과 두 번째 기사임이 확인된다. 프로그램을 수행하고 잠시 시간이 지난 후여서 약간 뒤로 기사가 밀렸지만, 정확하게 시간순으로 데이터를 반환하는 것을 확인할 수 있다.
이미 페이스북과 트위터를 진행하면서 많은 부분의 코드가 유사하게 사용되고 있어 특정 부분만 살펴 보도록 하자.
#[CODE 1]
def get_request_url(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
#이하 생략
우리는 네이버 개발자 애플리케이션을 등록한 후 Client ID와 Client Secret을 부여 받았다. 비인증 API 방식에서는 단순하게 Request 헤더부분에 ID와 Secret을 함께 전송함으로써 REST API를 사용할 수 있다.
#[CODE 2]
def getNaverSearchResult(sNode, search_text, page_start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % sNode
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(search_text), page_start, display)
url = base + node + parameters
#이하 생략
네이버 검색은 뉴스(news.json), 블로그(blog.json) 및 까페(cafearticle.json)의 요청 End Point 형식만 다르고 전달하는 매개 변수의 형식은 동일하다.
| query | 검색어 파라미터(UTF-8 인코딩 형식) |
| start | 검색의 시작점(최대값 1,000) |
| display | 1회 검색에 가지고 올 데이터 레코드 수(최대 100) |
| sort | sim(유사도순: 기본값), date(날짜순) |
앞에서 언급하였지만 3월 초 현재 ‘탄핵’이라는 검색어로 조회되는 기사는 43만건이다. 이를 REST API를 이용한다면, 1회 검색할 수 있는 display값이 100 이므로 4,300(430,000 / 100)회의 조회를 해야 한다. 그러나 검색의 시작점 최대가 1,000이므로 우리는 최대 1,099건의 데이터를 가지고 올 수 있다(start=999, display=100으로 전달 하는 경우). 결국 그 이후(시간상은 이전)의 데이터는 검색할 수 있는 방법이 없는 것이다(유료로 계약하면 달라질 것으로 예상한다).
#[CODE 3]
def getPostData(post, jsonResult):
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
#Tue, 14 Feb 2017 18:46:00 +0900
pDate = datetime.datetime.strptime(post['pubDate'], '%a, %d %b %Y %H:%M:%S +0900')
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S')
jsonResult.append({'title':title, 'description': description,
'org_link':org_link, 'link': org_link,
'pDate':pDate})
return
JSON 형식으로 수신되는 데이터는 [‘items’] 내부에 레코드 형태로 존재하며, 제목(title), 간단한 내용(description), 링크(link)를 공통으로 가지며 검색 영역(뉴스, 블로그, 까페 등)에 따라 고유한 네임을 가지고 있다. 예제 코드는 뉴스를 검색하여 저장하기 위한 형식이다. 자세한 부분은 네이버 개발자 페이지를 참고하기 바란다.