3. 명사 추출 및 빈도 분석
이번절에서는 앞에서 알아본 1. 빈도 분석 - KoNLPy 설치하기(문장 형태소 분석)을 이용하여 수집된 데이터의 명사를 추출하고 이를 2. 그래프를 그리자 : matplotlib를 이용하여 그래프로 표시하고, ‘pytagcloud’를 이용하여 워드클라우드로 표현해 본다.
먼저 데이터 수집을 위하여 페이스북의 조선일보(chosun)과 JTBC 뉴스(jtbcnews)를 ‘2016-10-01’부터 ‘2017-03-12’일 까지의 데이터를 PYTHON 크롤링 » 5. Facebook 데이터 수집에서 제작한 페이스북 크롤러를 이용하여 수집하였다. 먼저 다음과 같이 코드를 작성한다.
import json
import re
from konlpy.tag import Twitter
from collections import Counter
import matplotlib.pyplot as plt
import matplotlib
from matplotlib import font_manager, rc
import pytagcloud
import webbrowser
#[CODE 1]
def showGraph(wordInfo):
font_location = "c:/Windows/fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=font_location).get_name()
matplotlib.rc('font', family=font_name)
plt.xlabel('주요 단어')
plt.ylabel('빈도수')
plt.grid(True)
Sorted_Dict_Values = sorted(wordInfo.values(), reverse=True)
Sorted_Dict_Keys = sorted(wordInfo, key=wordInfo.get, reverse=True)
plt.bar(range(len(wordInfo)), Sorted_Dict_Values, align='center')
plt.xticks(range(len(wordInfo)), list(Sorted_Dict_Keys), rotation='70')
plt.show()
#[CODE 2]
def saveWordCloud(wordInfo, filename):
taglist = pytagcloud.make_tags(dict(wordInfo).items(), maxsize=80)
pytagcloud.create_tag_image(taglist, filename, size=(640, 480), fontname='korean', rectangular=False)
webbrowser.open(filename)
def main():
#여기서 파일의 경로는 실제 JSON 데이터가 저장된 경로이다
openFileName = 'd:/Temp/FB_DATA/chosun_facebook_2016-10-01_2017-03-12.json'
#openFileName = 'd:/Temp/FB_DATA/jtbcnews_facebook_2016-10-01_2017-03-12.json'
cloudImagePath = openFileName + '.jpg'
rfile = open(openFileName, 'r', encoding='utf-8').read()
jsonData = json.loads(rfile)
message = ''
#[CODE 3]
for item in jsonData:
if 'message' in item.keys():
message = message + re.sub(r'[^\w]', ' ', item['message']) + ' '
#[CODE 4]
nlp = Twitter()
nouns = nlp.nouns(message)
count = Counter(nouns)
#[CODE 5]
wordInfo = dict()
for tags, counts in count.most_common(50):
if (len(str(tags)) > 1):
wordInfo[tags] = counts
print ("%s : %d" % (tags, counts))
showGraph(wordInfo)
saveWordCloud(wordInfo, cloudImagePath)
if __name__ == "__main__":
main()
코드를 수행하여 ‘조선일보’와 ‘jtbc뉴스’에 대한 다빈도 명사를 확인하여 보면 [그림 1]과 [그림 2]와 같이 나타남을 확인할 수 있다.
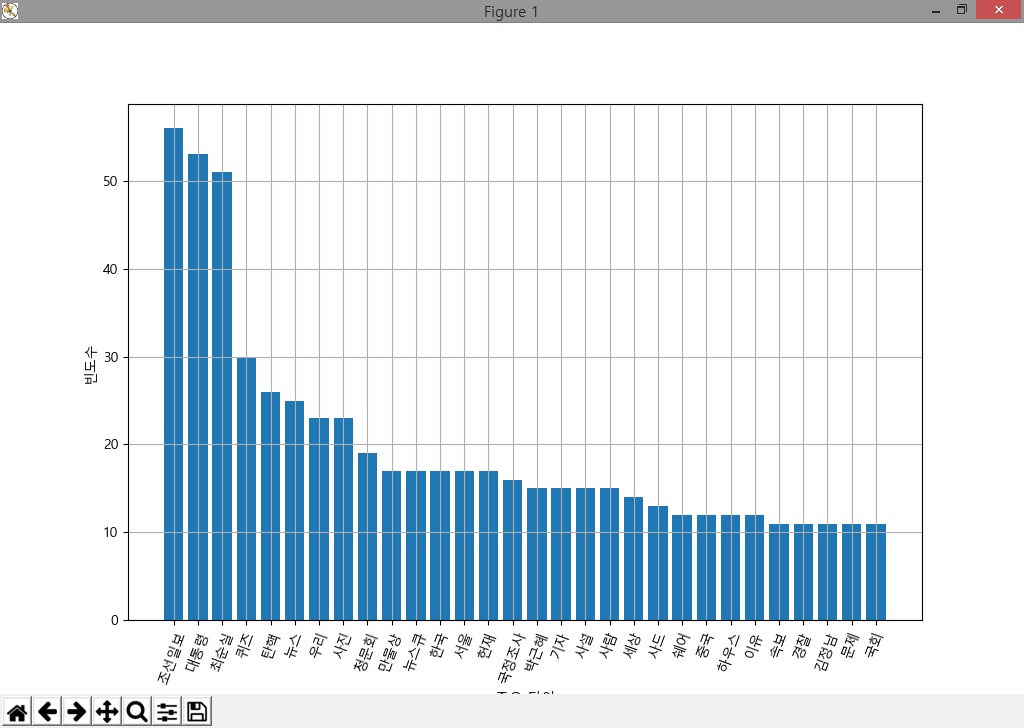 [그림 1] 조선일보 페이스북에서 2016-10-01~2017-03-12간 사용한 다빈도 명사
[그림 1] 조선일보 페이스북에서 2016-10-01~2017-03-12간 사용한 다빈도 명사
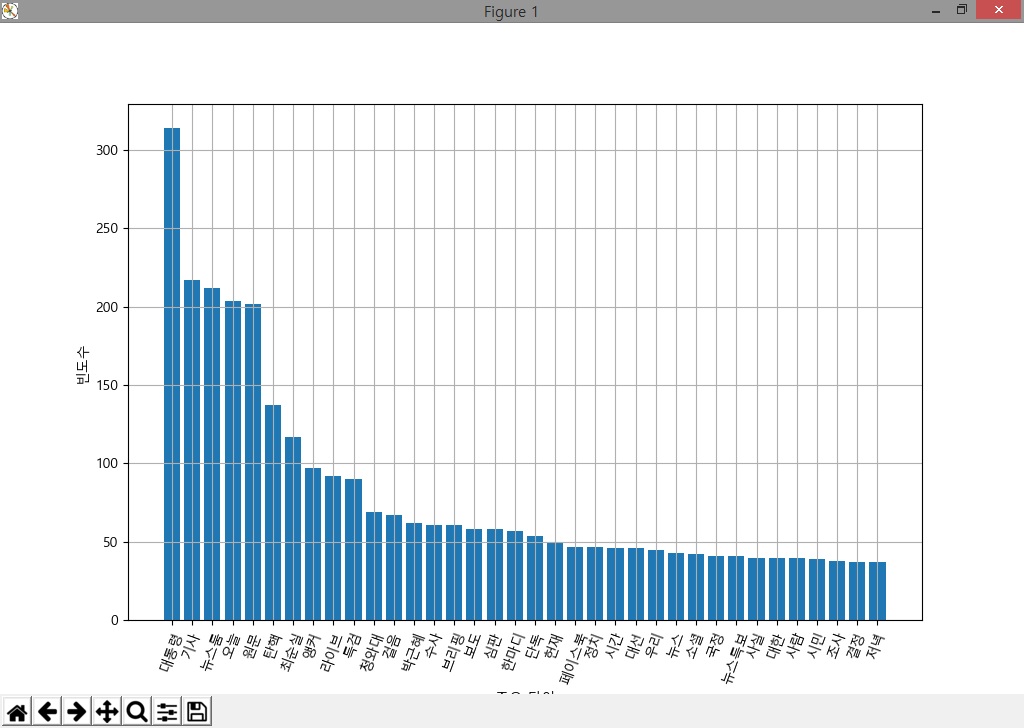 [그림 2] JTBC 페이스북에서 2016-10-01~2017-03-12간 사용한 다빈도 명사
[그림 2] JTBC 페이스북에서 2016-10-01~2017-03-12간 사용한 다빈도 명사
[그림 1]과 [그림 2]에서 보면 의미없는 명사들도 보이는데, 이러한 데이터는 분석을 위해서는 제제거 사용하는 것이 좋을 듯 하다. 조선일보의 경우에는 ‘최순실’이라는 단어가 ‘탄핵’이라는 단어보다 많이 나오지만, JTBC의 경우에는 반대 경우로 나타난다. 또한 ‘조선일보’의 경우에는 상대적으로 ‘박근혜’라는 이름을 적게 언급한 것으로 볼 수 있다. 또한 조선일보에서는 ‘사드’라는 단어가 보이자만 JTBC의 경우에는 상위 부분에서 ‘사드’라는 단어가 검색되지 않았음이 확인되었다. 그러나 전체 기사의 총수가 포함되지 않은 상태에서 이를 비교하기란 조금 억지스러운 부분이 있고, 추출된 데이터를 각 페이스북의 기사수로 정규화하여 비교하는 것이 의미있을 것이다.
[그림 3]과 [그림 4]는 해당 추출된 단어들을 가지고 워드 클라우드 - 글자들로 구성된 구름 모양의 그림이라고 해석해야 할 것 같다 – 를 생성한 것이다.
 [그림 3] 조선일보 페이스북 다빈도 명사 워드 클라우드
[그림 3] 조선일보 페이스북 다빈도 명사 워드 클라우드
 [그림 4] JTBC뉴스 페이스북 다빈도 명사 워드 클라우드
[그림 4] JTBC뉴스 페이스북 다빈도 명사 워드 클라우드
그럼 이제 코드를 살펴 보도록 하자.
#[CODE 1]
def showGraph(wordInfo):
font_location = "c:/Windows/fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=font_location).get_name()
matplotlib.rc('font', family=font_name)
plt.xlabel('주요 단어')
plt.ylabel('빈도수')
plt.grid(True)
Sorted_Dict_Values = sorted(wordInfo.values(), reverse=True)
Sorted_Dict_Keys = sorted(wordInfo, key=wordInfo.get, reverse=True)
plt.bar(range(len(wordInfo)), Sorted_Dict_Values, align='center')
plt.xticks(range(len(wordInfo)), list(Sorted_Dict_Keys), rotation='70')
plt.show()
[CODE 1]의 showGraph()는 wordInfo라고 하는 딕셔너리(Dictionary)형식의 데이터를 받아 막대 그래프를 그리는 함수이다. 먼저 한글 폰트를 지원하기 위하여 ‘fontmanager’와 ‘rc’를 사용하였고, 라벨에 값을 부여하였다. 딕셔너리 형식의 데이터에서 키값과 밸류값을 별도로 분리하여 리스트 형태고 작성하였으며, 최대빈도부터 표현하기 위하여 sorted()함수를 사용하였다. 이렇게 구성하면 ‘Sorted_Dict_Keys’와 ‘Sorted_Dict_Values’쌍에는 최대 빈도수값과 최대빈도수 단어가 저장되게 된다.
‘pyplot.bar(index, list, args…)’ 함수는 막대 그래프를 그리는 함수로 필수 인자로는 데이텅 인덱스(X축), 데이터 리스트값(인덱스에 해당하는 데이터값)이며 막대그래프의 폭(width), 색상(color), 에러편차값(yerr)등을 인자로 전달할 수 있다.
‘pyplot.xticks(index, list, args…)’ 함수는 x축의 각 데이터별 문자열(tick)을 지정한다. rotation을 사용하면 문자열을 회전시킬 수 있어 열에 표시하는 데이터가 많은 경우에는 좌우 문자열(tick)과 겹치지 않도록 하기 위하여 많이 사용한다.
#[CODE 2]
def saveWordCloud(wordInfo, filename):
taglist = pytagcloud.make_tags(dict(wordInfo).items())
pytagcloud.create_tag_image(taglist, filename, size=(640, 480), fontname='korean', rectangular=False)
webbrowser.open(filename)
파이썬은 워드클라우드를 만들기 위하여 다양한 패키지를 제공한다. 이중 일반적으로 많이 사용하는 패키지가 ‘pytagcloud’이다. 먼저 패키지 사용을 위하여 설치를 한다.
[파이썬 설치 경로]\\pip install pytagcloud
‘pytagcloud’도 역시 한글 폰트를 제공하지 않는다. ‘[파이썬이 설치된 경로]\Lib\site-packages\pytagclod\fonts’ 디렉터리로 이동하면 여러 개의 ‘.ttf’ 파일과 ‘font.json’파일이 [그림 5]와 같이 존재할 것이다(저자의 경우 파이썬이 설치된 경로는 D:\Program Files\Python이다)
 [그림 5] pytagcloud font 디렉터리
[그림 5] pytagcloud font 디렉터리
실제 ‘pytagcloud’ 코드를 확인해보면 기본 폰트로 ‘Droid Sans’ 지정되어 있고, fonts.json 파일을 참조하여 폰트를 가지고 오게 되어있다. 먼저 우리가 사용할 폰트를 윈도우 폰트 디렉터리에서(PYTHON 시각화 » 2.3 한글 처리에서 설명) 사용할 폰트를 복사하여 ‘[파이썬이 설치된 경로]\Lib\site-packages\pytagclod\fonts’ 디렉터리에 복사한 후 에디터를 이용하여 ‘fonts.json’ 파일을 [그림 6]과 같이 수정한다.
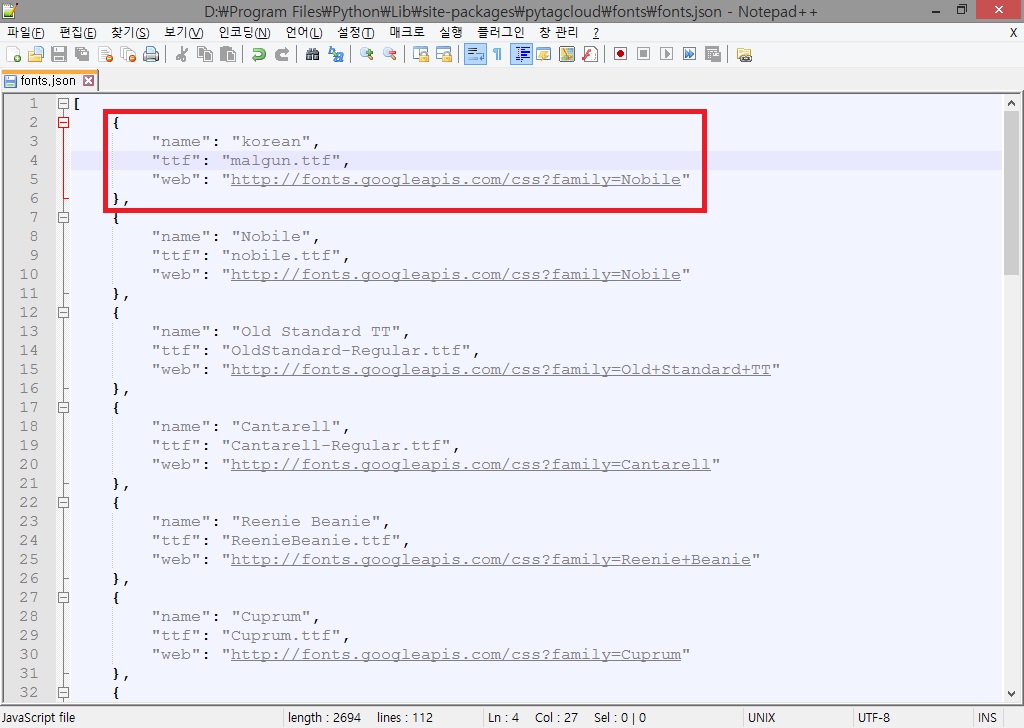 [그림 6] 한글 지원을 위한 fonts.json 파일의 수정
[그림 6] 한글 지원을 위한 fonts.json 파일의 수정
‘pytagcloud’는 사용하는 폰트 정보를 ‘fonts.json’에서 관리한다. font.json 파일을 다음과 같이 수정한다.
{
"name": "korean",
"ttf": "malgun.ttf",
"web": http://fonts.googleapis.com/css?family=Nobile
},
JSON 파일에서 접근할 폰트명과 실제 사용할 폰트파일을 지정해 준다. ‘pytagcloud’의 공식문서에는 자세하게 ‘web’에 대해 설명하고 있지 않는데 코드를 찾아 보아도 크게 쓰이는 부분을 확인하기 힘들다.
먼저 추출된 문자열을 리스트로 생성하여 pytagcloud.create_tag_image(데이터리스트, 저장할 파일명, 저장할 크기, fontname=’korean’, args…)함수로 전달한다. 여기서 ‘fontname’은 JSON 파일에서 지정한 ‘name’의 값을 지정한다. ‘pytagcloud.create_tag_image()’ 함수를 사용하면 간단하게 한줄로 워드 클라우드를 생성할 수 있다(역시 파이썬은 참 편하게 사용할 수 있는 언어이다).
저장된 파일은 ‘webbrowser’ 모듈은 open()함수를 이용하여 저장한 파일을 불러올 수 있다.
def main():
openFileName = 'd:/Temp/FB_DATA/chosun_facebook_2016-10-01_2017-03-12.json'
#openFileName = 'd:/Temp/FB_DATA/jtbcnews_facebook_2016-10-01_2017-03-12.json'
cloudImagePath = openFileName + '.jpg'
rfile = open(openFileName, 'r', encoding='utf-8').read()
jsonData = json.loads(rfile)
message = ''
#[CODE 3]
for item in jsonData:
if 'message' in item.keys():
message = message + re.sub(r'[^\w]', ' ', item['message']) + ' '
#[CODE 4]
nlp = Twitter()
nouns = nlp.nouns(message)
count = Counter(nouns)
#[CODE 5]
wordInfo = dict()
for tags, counts in count.most_common(50):
if (len(str(tags)) > 1):
wordInfo[tags] = counts
print ("%s : %d" % (tags, counts))
showGraph(wordInfo)
saveWordCloud(wordInfo, cloudImagePath)
if __name__ == "__main__":
main()
작성된 함수를 사용하기 위해서 main()에서는 JSON 형태로 저장된 페이스북 피드 파일을 불러와서 jsonData에 저장하고, [CODE 3]과 같이 ‘message’의 내용을 합쳐 하나의 문자열로 만드는 작업을 수행한다. 이 때 의 json 형태 파일중에 메시지 부분의 데이터를 불러와 이를 문자열로 구성한다. 정규식 처리를 한 이유는 ‘message’ 부분에 ‘\t’이나 ‘\n’등의 문자를 제거하기 위해서 문자나 숫자가 아닌 경우에는 공란(‘ ‘)으로 바꾼후 넣어 문자열을 작성한다.
[CODE 4]에서는 konlpy.tag의 Twitter() 품사 클래스를 이용하였다. ‘KoNLPy’는 Kkma, Komoranm Twitter, Mecab(윈도우에서는 사용 불가), Hannanum 등의 여러 품사 클래스가 있는데 사용을 해보면 긴 데이터를 넣는 경우에 일부 클래스에서는 응답이 상당히 늦거나 동작을 안하는 경우가 발생하였다. ‘Twitter()’ 클래스의 ‘nouns()’를 이용하여 명사만을 추출한 리스트를 작성한다.
작성된 명사 리스트는 Counter()를 이용하여(인스톨 안되어 있으면 추가) 개수를 세고, 이중에 most_common(50) 함수를 이용하여 상위 50개의 리스트를 가지고 온다. 이 때 실제 명사가 한글자인경우는 제외하였는데 의미있는 명사일 수 있지만 품사클래스에 따라 의미없는 것이 많으므로 제외하였다(필터 함수를 제작하여 걸러내는것도 의미 있을 것이다).
우리는 이번절에서 KoNLPy와 PyTagCloud 패키지를 이용하여 데이터열에서 간단하게 명사만을 추출하고, 이를 워드클라우드 형태의 이미지 파일로 생성하는 방법을 알아 보았다. 파이썬은 편의성을 확장하기 위하여 계속 진화하고 있으며, 수많은 개발자들에 의하여 다양한 모듈이 매일 개발되거나 업그레이드되고 있어 어디까지 우리를 편하게 해줄기 상상만해도 즐겁다.