4. 데이터 기반 추천: 데이터 상관 관계 분석
요즘 빅데이터 열풍이 불면서 ‘추천서비스’에 대한 이야기가 많이 들린다. 데이터를 분석해서 사용자에게 필요한 정보를 ‘맞춤형’으로 제공하고자 하는 시도는 여러곳에서 수행되고 있으며 그중에서 가장 많이 사용하는 분석 방법중 한가지가 ‘상관관계 분석’이다. 통계학도가 아니여도 ‘상관관계 분석’이라는 말은 데이터 분석에 관심이 있다면 한번쯤은 들어 보았을 것이다. 간단하게 ‘상관관계 분석’이 어떤 것인지 알아보고 이를 데이터 분석에 활용하는 방법에 대해 알아보자.
4.1 상관분석과 상관계수
우리는 일상생활에서 “키가 크면 발이 크다”, “교육수준이 높을수록 자녀의 대학 진학률이 높다”등의 이야기를 많이 한다. 이러한 두 개의 변수 ‘키’와 ‘발’, ‘교육수준’과 ‘자녀 대학 진학률’간의 관계가 어떠한 관계를 가지고 있는지 성향을 분석하는 것이 “상관분석”이다. 이를 ‘산포도’ 또는 ‘산점도’라는 그래프로 그리면 직관적으로 두 변수간의 관계를 파악할 수 있다.
만약 어느 집단의 키와 발크기를 조사하였더니 다음의 표와 같이 정리가 되었다고 하자(극단적인 예를 만든것임).
| 키(Cm) | 100 | 120 | 130 | 140 | 150 | 160 | 170 | 180 | 190 |
| 발크기(mm) | 200 | 205 | 210 | 220 | 230 | 250 | 270 | 280 | 285 |
직관적으로 표만 보아도 키가 커지면 발크기가 커지는 것을 확인할 수 있다. 이를 산포도로 그려보기 위하여 다음과 같이 코드를 작성해 보자.
>>> import matplotlib.pyplot as plt
>>> from matplotlib import font_manager, rc
>>> import matplotlib
>>> font_location = "c:/Windows/fonts/malgun.ttf"
>>> font_name = font_manager.FontProperties(fname=font_location).get_name()
>>> matplotlib.rc('font', family=font_name)
>>> height = [100, 120, 130, 140, 150, 160, 170, 180, 190]
>>> foot_size = [200, 205, 210, 220, 230, 250, 270, 280, 285]
>>> plt.scatter(height, foot_size)
>>> plt.xlabel('키(Cm)')
>>> plt.ylabel('발크기(mm)')
>>> plt.show()
코드를 수행하면 [그림 1]과 같이 그려진다. 그래프로 그려보니 더욱더 확실하게 증가하는 형태가 보인다.
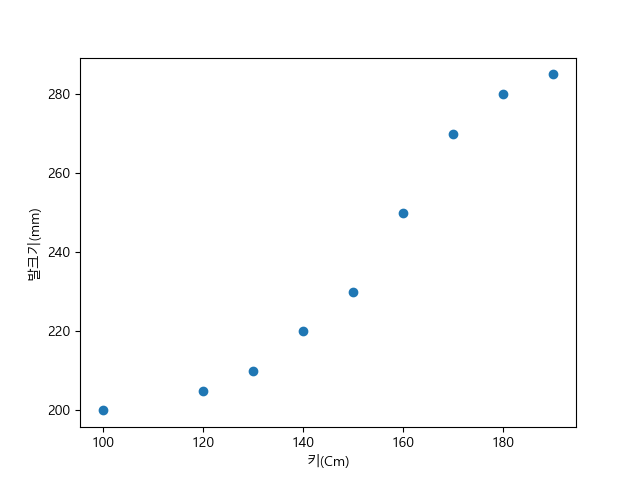 [그림 1] x가 증가함에 따라 y가 증가하는 경우
[그림 1] x가 증가함에 따라 y가 증가하는 경우
다음으로 산의 높이에 따른 온도의 변화를 표로 나타내보자(일반적으로 산의 높이가 100m 올라갈때마다 평균 0.65℃ ~ 0.75℃ 정도 낮아진다고 한다)
| 산의 높이(m) | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 |
| 온도(℃) | 18.0 | 17.5 | 17 | 16.5 | 15 | 14.5 | 13 | 12 | 11 |
위의 표를 이용하여 산포도를 그려보자.
>>> height = [100, 200, 300, 400, 500, 600, 700, 800, 900]
>>> temperature = [18.0, 17.5, 17, 16.5, 15, 14.5, 13, 12, 11]
>>> plt.scatter(height, temperature)
>>> plt.xlabel('산의높이(m)')
>>> plt.ylabel('온도(℃)')
>>> plt.show()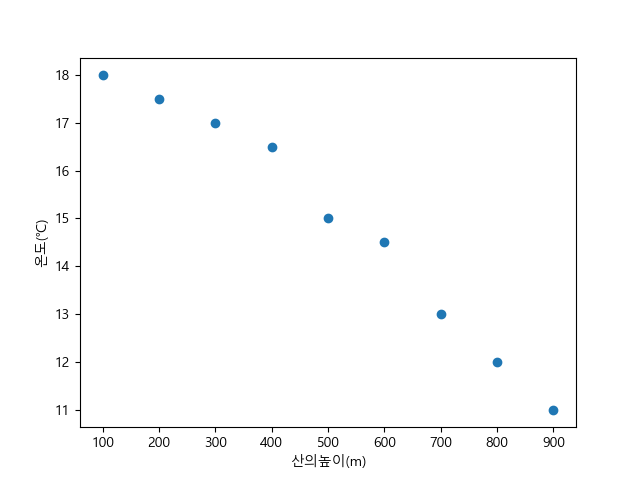 [그림 2] 산의 높이에 따른 온도의 변화
[그림 2] 산의 높이에 따른 온도의 변화
[그림 2]에서 보듯이 산의 높이가 높아질수록 온도가 낮아짐을 확인할 수 있다. 다음의 코드를 작성해 보자.
>>> import numpy as np
>>> random_x = np.random.random_integers(0, 100, 50)
>>> random_y = np.random.random_integers(0, 100, 50)
>>> plt.scatter(random_x, random_y)
>>> plt.show()
위의 코드를 생성하면 [그림 3]과 같이 어떤 관계가 보이지 않는 데이터가 나타난다.
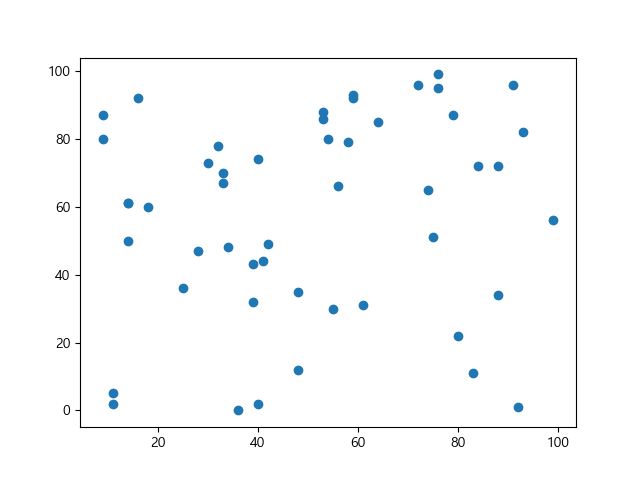 [그림 3] 데이터간의 관계가 보이지 않는 경우
[그림 3] 데이터간의 관계가 보이지 않는 경우
이 예제에서는 데이터 연관성을 없애기 위하여 numpy모듈의 random_interger()함수를 사용하였다. ‘random_interger(arg1, arg2, number)’는 ‘arg1’과 ‘arg2’사이의 임의의 난수를 ‘number’ 개수만큼 만들어준다.
상관분석에서는 x의 값이 증가함에 따라 y의 값이 증가하는 경우 우리는 “양의 상관관계”를 가지고 있다고 이야기하며(키 vs. 발크기), 반대로 x가 증가함에 따라 y의 값이 감소(산의 높이 vs. 온도)하는 경우 “음의 상관관계”를 가지고 있다고 이야기한다.
상관 계수는 서로간의 데이터가 어느 정도의 근접도를 가지고 있는지 표현하는 방법이다. [그림 4]는 둘 다 양의 상관관계를 가지고 있으나 두 점들이 모여있는 근접도(밀도)가 차이를 가진다.
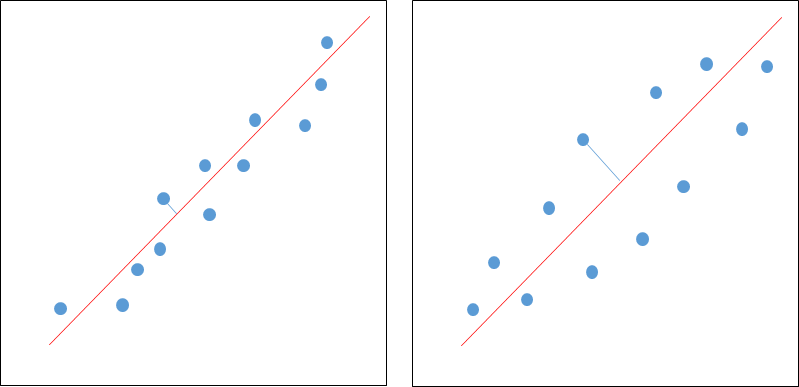 [그림 4] 양의 상관관계를 가지고 있으나 근접도가 다른 경우
[그림 4] 양의 상관관계를 가지고 있으나 근접도가 다른 경우
이러한 근접도를 함께 포함하도록 표현한 방법이 “상관계수(기호로는 r)”이다. 상관계수는 -1≤r≤1 의 값을 가지며, 수치가 0에 근접할 수록 두 변수간에 상관관계가 없음을 의미하고, -1의 경우에는 음(-)의 상관 관계가 강하며, +1에 근접할수록 양(+)의 상관관계가 크다고 본다.
일반적으로 각 상관계수 값은 다음과 같은 의미로 해석된다(음의 상관계수는 절대값을 붙여 생각하면 된다). 이 해석은 분석하는 사람에 따라 편차가 있다.
| 0.0 ~ 0.2 | 상관 관계가 거의 없다 |
| 0.2 ~ 0.4 | 약한 상관 관계 |
| 0.4 ~ 0.6 | 상관 관계가 있다 |
| 0.6 ~ 0.8 | 강한 상관 관계 |
| 0.8 ~ 1.0 | 매우 강한 상관 관계 |
상관관계 분석식은 다음과 같이 표현된다.
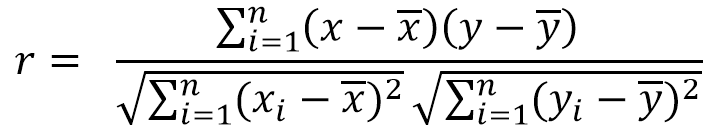
4.2 데이터 테이블 생성: pandas 패키지
‘pandas’ 패키지는 데이터를 엑셀 스프레드시트(excel spreadsheet)나 SQL 테이블과 같이 서로 다른 속성을 가지는 컬럼들로 구성된 데이터 테이블 형태(DataFrame)이나 시계열 데이터와 같이 연속된 데이터 셋(Series)으로 구성하고, 이를 분석하기 위한 도구로 사용된다.
‘pandas’ 패키지는 데이터 구조를 위하여 일차원 데이터인 ‘Series’와 이차원 데이터인 ‘DataFrame’을 사용한다. 먼저 파이썬 에뮬레이터를 실행하고 ‘pandas’와 ‘numpy’를 ‘import’한다. ‘numpy’는 파이썬을 이용하여 과학 계산과 같은 고성능 수치계산을 위해 만들어진 패키지로써 다차원 배열을 사용하기 위하여 주로 사용한다(‘numpy’에 대한 활용은 필요한 부분에서만 잠시 하겠다).
>>> import numpy as np
>>> import pandas as pd4.2.1 Series
‘Series’는 이차원의 인덱스를 가지는 배열(labeled array)로써 integer, string, float, 파이썬 객체(object)등 다양한 형식의 데이터 타입을 가질 수 있으며 함수의 사용법은 다음과 같다.
pd.Series(data, index=index)
1) 일차원(array) 데이터의 활용
>>> s = pd.Series(np.random.randn(5))
>>> s
0 0.636579
1 1.429441
2 -0.056851
3 -0.330899
4 0.690789
dtype: float64
>>> s = s = pd.Series(np.random.randn(5), index=['A','B','C','D','E'])
>>> s
A 0.449761
B -0.288997
C -0.263346
D 1.673738
E -0.437203
dtype: float64
두 예제에서 보듯이, 인덱스의 값을 부여하지 않으면 ‘pandas’는 자동적으로 0부터 len(data)-1까지의 값을 부여하며, 인덱스 값을 부여하는 경우에는 해당 인덱스로 매칭된다. 인덱스를 부여하는 경우에는 인덱스의 개수와 데이터의 개수가 반듯이 일치하여야 한다.
‘numpy’에서 가장 많이 사용하는 ‘ndarray’는 ‘N’차원의 배열 객체로써 기존의 파이썬은 어떠한 형식이라도 어레이에 담을 수 있으나, ‘ndarray’는 동일한 형태의 데이터만 배열에 담을 수 있는 차이점을 가지고 있다. 우리가 자료를 임의로 생성하여는 경우가 많으므로 난수(random) 데이터를 얻는 함수에 대해 살펴보자
| rand(d0, d1, …, dn) | N차원 배열의 난수 발생 |
| randn(d0, d1, …, dn) | 표준 정규분포에 따른 N차원 난수 발생 |
| randint(low[, high, size]) | low 이상 high 미만의 정수형 난수 발생 |
| random_integers(low[, high, size]) | low이상 high이하의 정수형 난수 발생 |
| random_sample([size]) random([size]) ranf([size]) sample([size]) |
0.0이상 1.0미만의 실수형 난수 발생 |
| choice(a[, size, replace, p]) | 주어진 1차원 배열을 기반으로 무작위 샘플 추출 |
| bytes(length) | 바이트형 난수 발생 |
2) 딕셔너리(Dictionary)
>>> d = {'a' : 0., 'b' : 1., 'c' : 2.}
>>> pd.Series(d)
a 0.0
b 1.0
c 2.0
dtype: float64
>>> pd.Series(d, index=['a', 'b', 'B', 'c'])
a 0.0
b 1.0
B NaN
c 2.0
dtype: float64
딕셔너리 형태의 데이터는 인덱스를 부여하지 않으면 딕셔너리 키값이 인덱스로 들어가며, 만약 ‘index값을 지정하는 경우에는 데이터 값에서 해당 인덱스의 값만을 가지고 들어온다. 위의 예에서 ‘d’인덱스에는 ‘B’가 없으므로 생성된 시리즈에는 ‘B’의 값이 ‘NaN(Not a Number)‘으로 들어가 있게 된다.
3) 스칼라(Scalar) 값
>>> pd.Series(7, index=['a', 'b', 'c', 'd', 'e'])
a 7
b 7
c 7
d 7
e 7
dtype: int64
스칼라 값을 이용하여 초기화를 하는 경우에는 반듯이 인덱스가 들어가야 한다.
생성된 데이터의 값을 가지고 오는 방법은 배열에서 데이터를 가지고 오는 방법과 동일한 형식을 가지고 있으며 데이터 연산이 다음과 같이 가능하다.
>>> s = pd.Series([1,2,3,4,5], index=['a', 'b', 'c', 'd', 'e'])
>>> s[0]
1
>>> s[:3]
a 1
b 2
c 3
dtype: int64
>>> s[[4,1]]
e 5
b 2
dtype: int64
>>> np.power(s, 2)
a 1
b 4
c 9
d 16
e 25
dtype: int644.2.2 DataFrame
‘DataFrame’은 가장 많이 사용하는 ‘pandas’의 객체로 엑셀과 같이 표의 형식으로 데이터를 표현할수 있어 다양한 형태로 데이터 분석에 사용된다. ‘DataFrame’은 각개의 열은 데이터 형식이 동일하지만 서로 다른 열끼리는 데이터의 형식이 달라도 되기 때문에 하나의 테이블 형태로 데이터를 표현하기에 적합한 형태이다.
1) Series/Dict 데이터의 활용
>>> d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
>>> d
{'two':
a 1.0
b 2.0
c 3.0
d 4.0
dtype: float64,
'one':
a 1.0
b 2.0
c 3.0
dtype: float64}
>>> df = pd.DataFrame(d)
>>> df
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
>>> d = {'one' : pd.Series([1., 2., 3.]),
'two' : pd.Series([1., 2., 3., 4.])}
>>> df = pd.DataFrame(d)
>>> df
one two
0 1.0 1.0
1 2.0 2.0
2 3.0 3.0
3 NaN 4.0
>>> d = {'one' : [1., 2., 3., 4.],
'two' : [4., 3., 2., 1.]}
>>> df = pd.DataFrame(d)
>>> df
one two
0 1.0 4.0
1 2.0 3.0
2 3.0 2.0
3 4.0 1.0
결과값을 보면 알 수 있듯이 인덱스의 값은 다른 한쪽이 없는 경우에는 해당 인덱스를 가지면서 값에는 ‘NaN’를 입력하게 된다. 만약 인덱스 값을 부여하지 않으면 자동으로 0부터 두개의 데이터 중 큰 배열의 길이 – 1 만큼이 부여된다.
2) Dict 리스트 데이터의 활용
>>> data2 = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
>>> pd.DataFrame(data2)
a b c
0 1 2 NaN
1 5 10 20.0
>>> pd.DataFrame(data2, index=['first', 'second'])
a b c
first 1 2 NaN
second 5 10 20.0
>>> pd.DataFrame(data2, columns=['a', 'b'])
a b
0 1 2
1 5 10
>>> df.rename(columns={'a':'COL1'})
COL1 b
0 1 2
1 5 10
>>> df.set_index('b')
a
b
2 1
10 5
‘Dict List’는 가장 많이 사용하는 데이터 형식으로 내가 원하는 열의 값만 선택하여 하나의 테이블로 만들 수 있는 장점이 있다. 또한 rename()을 이용하여 지정한 열의 이름을 바꿀 수 있으며 특정 열을 인덱스 열로 변경할 수 있다.
3) 데이터 추가 및 합치기(merge)
>>> data1 = [{'name':'Mark'},{'name':'Eric'},{'name':'Jennifer'}]
>>> df = pd.DataFrame(data1)
>>> df
name
0 Mark
1 Eric
2 Jennifer
>>> df['age'] = [10, 11, 12]
>>> df
name age
0 Mark 10
1 Eric 11
2 Jennifer 12
>>> data2 = [{'sido':'서울'}, {'sido':'경기'}, {'sido':'인천'}]
>>> df2 = pd.DataFrame(data2)
>>> df2
sido
0 서울
1 경기
2 인천
>>> pd.merge(df1, df2, left_index=True, right_index=True)
name sido
0 Mark 서울
1 Eric 경기
2 Jennifer 인천
기존의 ‘DataFrame’에 새로운 행을 추가하는 것은 단순하게 컬럼명을 부여하고 데이터 리스트를 만들어 주면 된다. 또한 서로 다른 두개의 ‘DataFrame’을 원하는 형식대로 합치기 위하여 ‘merge()’ 함수를 제공한다. ‘merge()’ 함수는 SQL문과 유사하게 여러 형태의 조인(join)을 수행할 수 있으며, 양 쪽 ‘DataFrame’이 인덱스를 가지고 있을 경우 이를 이용하여 동일한 행으로 추출하여 새로운 테이블을 만들 수 있다. 이외에도 ‘appen()’를 이용하면 동일한 형식의 ‘DataFrame’을 연결할 수 있다.
‘pandas’는 상당히 광범위한 패키지여서 여기서는 우리가 사용하는데 필요한 기능만을 간략하게 설명하였다. 좀더 자세한 사항은 공식 페이지의 매뉴얼을 확인하기 바란다.
4.3 공공데이터를 이용한 상관분석
이번절에서는PYTHON 크롤링 » 10. 공공 정보 데이터 수집하기 에서 수집한 데이터를 이용하여 데이터 분석을 수행하고자 한다. 데이터셋을 만들기 위하여 2011년 1월부터 2016년 9월까지의 서울특별시 유료 관광지 입장 정보 파일을 JSON 형태로 저장한다. 그리고 중국, 일본, 미국인의 입국수 정보를 JSON으로 저장한다. 이제 저장이 완료되었으면 다음과 같이 코드를 작성한다.
저장된 JSON 파일 : 서울특별시_관광지입장정보_2011_2016.json / 중국(112)_해외방문객정보_2011_2016.json / 일본(130)_해외방문객정보_2011_2016.json / 미국(275)_해외방문객정보_2011_2016.json
import json
import math
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from matplotlib import font_manager, rc
import pandas as pd
#[CODE 1]
def correlation(x, y):
n = len(x)
vals = range(n)
x_sum = 0.0
y_sum = 0.0
x_sum_pow = 0.0
y_sum_pow = 0.0
mul_xy_sum = 0.0
for i in vals:
mul_xy_sum = mul_xy_sum + float(x[i]) * float(y[i])
x_sum = x_sum + float(x[i])
y_sum = y_sum + float(y[i])
x_sum_pow = x_sum_pow + pow(float(x[i]), 2)
y_sum_pow = y_sum_pow + pow(float(y[i]), 2)
try:
r = ((n * mul_xy_sum) - (x_sum * y_sum)) / math.sqrt( ((n*x_sum_pow) - pow(x_sum, 2)) * ((n*y_sum_pow) - pow(y_sum, 2)) )
except:
r = 0.0
return r
#[CODE 2]
def setScatterGraph(tour_table, visit_table, tourpoint):
#[CODE 8]
tour = tour_table[tour_table['resNm'] == tourpoint]
merge_table = pd.merge(tour, visit_table, left_index=True, right_index=True)
fig = plt.figure()
fig.suptitle(tourpoint + '상관관계 분석')
plt.subplot(1, 3, 1)
plt.xlabel('중국인 입국수')
plt.ylabel('외국인 입장객수')
r = correlation(list(merge_table['china']), list(merge_table['ForNum']))
plt.title('r = {:.5f}'.format(r))
plt.scatter(list(merge_table['china']), list(merge_table['ForNum']), edgecolor='none', alpha=0.75, s=6, c='black')
plt.subplot(1, 3, 2)
plt.xlabel('일본인 입국수')
plt.ylabel('외국인 입장객수')
r = correlation(list(merge_table['japan']), list(merge_table['ForNum']))
plt.title('r = {:.5f}'.format(r))
plt.scatter(list(merge_table['japan']), list(merge_table['ForNum']), edgecolor='none', alpha=0.75, s=6, c='black')
plt.subplot(1, 3, 3)
plt.xlabel('미국인 입국수')
plt.ylabel('외국인 입장객수')
r = correlation(list(merge_table['usa']), list(merge_table['ForNum']))
plt.title('r = {:.5f}'.format(r))
plt.scatter(list(merge_table['usa']), list(merge_table['ForNum']), edgecolor='none', alpha=0.75, s=6, c='black')
plt.tight_layout()
#fig = matplotlib.pyplot.gcf()
#fig.set_size_inches(10, 7)
#fig.savefig(tourpoint+'.png', dpi=300)
plt.show()
def main():
font_location = "c:/Windows/fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=font_location).get_name()
matplotlib.rc('font', family=font_name)
#[CODE 4]
tpFileName = 'd:/Temp/public_data/서울특별시_관광지입장정보_2011_2016.json'
jsonTP = json.loads(open(tpFileName, 'r', encoding='utf-8').read())
tour_table = pd.DataFrame(jsonTP, columns=('yyyymm', 'resNm', 'ForNum'))
tour_table = tour_table.set_index('yyyymm')
#[CODE 5]
resNm = tour_table.resNm.unique()
#[CODE 6]
fv_CFileName = 'd:/Temp/public_data/중국(112)_해외방문객정보_2011_2016.json'
jsonFV = json.loads(open(fv_CFileName, 'r', encoding='utf-8').read())
china_table = pd.DataFrame(jsonFV, columns=('yyyymm', 'visit_cnt'))
china_table = china_table.rename(columns={'visit_cnt': 'china'})
china_table = china_table.set_index('yyyymm')
fv_JFileName = 'd:/Temp/public_data/일본(130)_해외방문객정보_2011_2016.json'
jsonFV = json.loads(open(fv_JFileName, 'r', encoding='utf-8').read())
japan_table = pd.DataFrame(jsonFV, columns=('yyyymm', 'visit_cnt'))
japan_table = japan_table.rename(columns={'visit_cnt': 'japan'})
japan_table = japan_table.set_index('yyyymm')
fv_UFileName = 'd:/Temp/public_data/미국(275)_해외방문객정보_2011_2016.json'
jsonFV = json.loads(open(fv_UFileName, 'r', encoding='utf-8').read())
usa_table = pd.DataFrame(jsonFV, columns=('yyyymm', 'visit_cnt'))
usa_table = usa_table.rename(columns={"visit_cnt": "usa"})
usa_table = usa_table.set_index('yyyymm')
#[CODE 7]
fv_table = pd.merge(china_table, japan_table, left_index=True, right_index=True)
fv_table = pd.merge(fv_table, usa_table, left_index=True, right_index=True)
for tourpoint in resNm:
setScatterGraph(tour_table, fv_table, tourpoint)
if __name__ == "__main__":
main()
코드를 수행하면 서울시 입장객과 각국 입국수에 따른 상관분석 자료가 [그림 5]와 같이 나타난다.
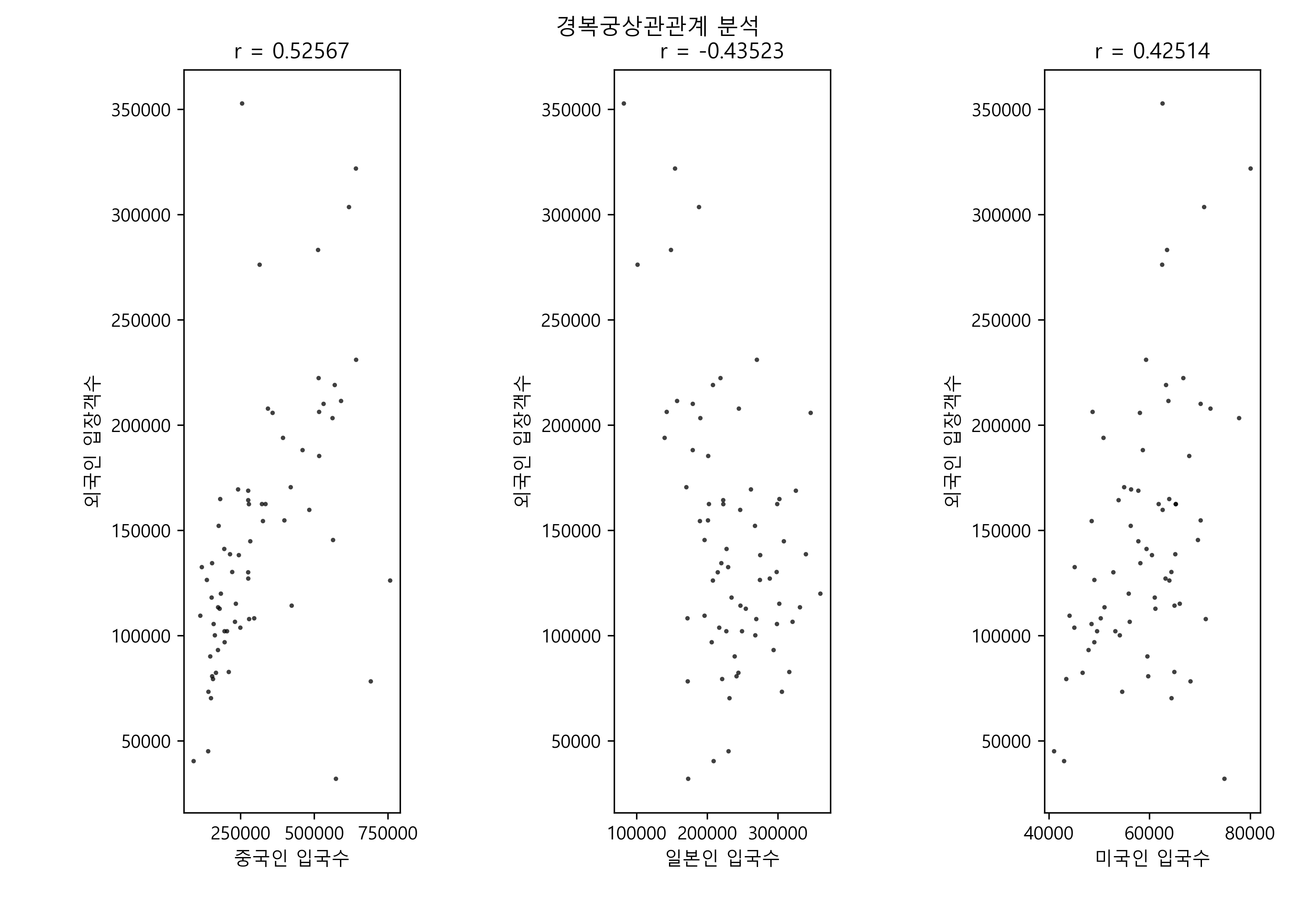 [그림 5] 경복궁 입장객 상관관계 분석
[그림 5] 경복궁 입장객 상관관계 분석
그럼 이제 코드를 살펴 보도록 하자. [CODE 1]은 파이썬으로 상관관계 분석을 하는 함수이다. ‘scipy’를 이용하면 상관분석 계수가 하나의 함수로 간단하게 나오지만, 여기서는 상관분석 함수를 직접 작성하여 보았다.
[CODE 2]는 ‘scatter()’ 함수를 이용하여 그래프를 그린다. 1 x 3 의 형태로 나타내기 위하여 subplot()함수를 사용하였다. ‘pyplot’의 그래프는 앞절에서 설명하였으므로 참고하기 바란다(내용중 [CODE 8]에 대한 설명은 잠시 후 하기로 한다).
본 과정에서는 데이터를 어떻게 분석하는가에 관점이 맞추어져 있으므로 python 쉘에서 [CODE 4], [CODE 5], [CODE 6]을 통해 ‘DataFrame’을 어떻게 사용하는지 설명하도록 하겠다. 먼저 저장된 파일이 JSON 형태이므로 ‘json’을 ‘import’하고 ‘DataFrame’을 위하여 ‘pandas’를 ‘import’ 한다.
>>> import json
>>> import pandas as pd
‘import’를 마치면 저장한 서울특별시 유료 관광객 파일을 JSON 형태로 읽어들여와 ‘DataFrame’으로 변환한다([CODE 4] 부분).
>>> tpFileName = 'd:/Temp/public_data/서울특별시_관광지입장정보_2011_2016.json'
>>> jsonTP = json.loads(open(tpFileName, 'r', encoding='utf-8').read())
>>> tour_table = pd.DataFrame(jsonTP)
>>> tour_table.head()
로드된 ‘tour_table’은 다음과 같은 형태로 표현된다(‘DataFrame’의 값을 보고자 할 때는 ‘.head()’를 사용하면 맨 앞 5개의 데이터를 보여준다. 괄호안에 숫자를 넣으면 해당 숫자만큼 열을 반환하며 기본값은 n=5이다).
| ForNum | NatNum | addrCd | gungu | resNm | rnum | sido | yyyymm | |
|---|---|---|---|---|---|---|---|---|
| 0 | 14137 | 43677 | 1111 | 종로구 | 창덕궁 | 1 | 서울특별시 | 201101 |
| 1 | 0 | 6523 | 1111 | 종로구 | 운현궁 | 2 | 서울특별시 | 201101 |
| 2 | 40224 | 141183 | 1111 | 종로구 | 경복궁 | 3 | 서울특별시 | 201101 |
| 3 | 697 | 17644 | 1111 | 종로구 | 창경궁 | 4 | 서울특별시 | 201101 |
| 4 | 6837 | 11486 | 1111 | 종로구 | 종묘 | 5 | 서울특별시 | 201101 |
상기 표에서 보듯이 JSON 형식의 각 키에 해당하는 값들이 테이블의 형태로 간단하게 입력된것을 확인할 수 있다. 그러나 우리는 모든 데이터를 사용할 것이 아니고 외국인 입장객수와, 관광지명, 그리고 입장년월만이 필요하므로 ‘column’ 인자를 사용하여 데이터를 불러온다
>>> tour_table = pd.DataFrame(jsonTP, columns=('yyyymm', 'resNm', 'ForNum'))
>>> tour_table.head()| yyyymm | resNm | ForNum | |
|---|---|---|---|
| 0 | 201101 | 창덕궁 | 14137 |
| 1 | 201101 | 운현궁 | 0 |
| 2 | 201101 | 경복궁 | 40224 |
| 3 | 201101 | 창경궁 | 697 |
| 4 | 201101 | 종묘 | 6837 |
데이터 처리에 필요한 ‘yyyymm’, ‘resNm’, ‘ForNum’만을 ‘column’의 인자값으로 주어 필요한 데이터만 추출하였다. 이제 출입국자들의 정보와 나중에 합치기 위하여 ‘연월’에 해당하는 ‘yyyymm’을 ‘set_index()’를 이용하여 인덱스 값으로 지정한다.
>>> tour_table = tour_table.set_index('yyyymm')
>>> tour_table.head(3)
resNm ForNum
yyyymm
201101 창덕궁 14137
201101 운현궁 0
201101 경복궁 40224
저장된 데이터 프레임에서 서울시 유료 관광지로 통계가 잡히는 곳이 어떤 곳인지 확인하기 위하여 ‘unique()’ 함수를 사용할 수 있다. ‘unique()’를 사용하면 해당 컬럼의 중복되지않는 값만을 확인할 수 있다([CODE 5] 부분).
>>> resNm = tour_table.resNm.unique()
>>> resNm
array(['창덕궁', '운현궁', '경복궁', '창경궁', '종묘', '국립중앙박물관', '서울역사박물관', '덕수궁',
'서울시립미술관 본관', '태릉·강릉·조선왕릉전시관', '서대문형무소역사관', '서대문자연사박물관',
'트릭아이미술관', '헌릉ㆍ인릉', '선릉·정릉', '롯데월드'], dtype=object)
서울시의 유료 관광객 입장수가 집계되는 곳은 경복궁, 종묘 등 총 16군데이다. 이 값을 ‘resNm’ 부분에 저장해서 추후에 데이터를 불러오는 키값으로 사용한다.
이제 앞장에서 저장한 JSON 형식의 국가별 입국 정보를 ‘DataFrame’으로 변환하고 인덱스 값을 ‘yyyymm’ 컬럼으로 대치한다([CODE 6] 부분)
>>> fv_CFileName = 'd:/Temp/public_data/중국(112)_해외방문객정보_2011_2016.json'
>>> jsonFV = json.loads(open(fv_CFileName, 'r', encoding='utf-8').read())
>>> china_table = pd.DataFrame(jsonFV, columns=('yyyymm', 'visit_cnt'))
>>> china_table.head()
yyyymm visit_cnt
0 201101 91252
1 201102 140571
2 201103 141457
3 201104 147680
4 201105 154066
>>> china_table = china_table.rename(columns={'visit_cnt': 'china'})
>>> china_table = china_table.set_index('yyyymm')
>>> china_table.head()
china
yyyymm
201101 91252
201102 140571
201103 141457
201104 147680
201105 154066
동일한 방식으로 일본인 입국수와 미국인 입국수를 처리한후 다음과 같이 국가별 입국수를 합쳐서 하나의 데이터 프레임으로 만든다.
>>> fv_table = pd.merge(china_table, japan_table, left_index=True, right_index=True)
>>> fv_table.head()
china japan
yyyymm
201101 91252 209184
201102 140571 230362
201103 141457 306126
201104 147680 239075
201105 154066 241695
>>> fv_table = pd.merge(fv_table, usa_table, left_index=True, right_index=True)
>>> fv_table.head()
china japan usa
yyyymm
201101 91252 209184 43065
201102 140571 230362 41077
201103 141457 306126 54610
201104 147680 239075 59616
201105 154066 241695 59780
이제 각 입국자 숫자가 하나의 데이터 프레임으로 만들어 졌으니 ‘resNM’에서 추출하는 관광지 이름과, ‘tour_table’, ‘fv_table’을 인자로 하여 ‘setScatterGraph()’ 함수를 호출하면 함수 내부에서는 전달받은 인자값으로 데이터 프레임을 생성한다. 다음의 예는 ‘경복궁’을 관광지 이름으로 받았다는 전제하에서 수행한다([CODE 8] 부분).
>>> tour = tour_table[tour_table['resNm'] == '경복궁']
>>> tour.head()
resNm ForNum
yyyymm
201101 경복궁 40224
201102 경복궁 44906
201103 경복궁 73166
201104 경복궁 89972
201105 경복궁 80539
>>> merge_table = pd.merge(tour, fv_table, left_index=True, right_index=True)
>>> merge_table.head()
resNm ForNum china japan usa
yyyymm
201101 경복궁 40224 91252 209184 43065
201102 경복궁 44906 140571 230362 41077
201103 경복궁 73166 141457 306126 54610
201104 경복궁 89972 147680 239075 59616
201105 경복궁 80539 154066 241695 59780
전달받은 ‘tour_table’은 16개 관광지에 대한 모든 데이터를 가지고 있기 때문에 계산할 관광지명에 해당하는 데이터만을 뽑아 ‘tour’ 데이터 프레임에 저장하고 이를 전달받은 외국인 방문객 데이터 프레임과 병합(merge)시키면 우리가 지정한 관광지에 대한 입장객수, 입국 외국인수가 결합된 데이터 프레임이 완성된다. 이제 그래프를 그리기 위하여 입장객수(ForNum)과 해당 국가(china, japan, 또는 usa) 열을 scatter()함수로 전달하면 원하는 그래프와 상관계수 값을 얻게 된다.
[CODE 9]에서는 함수를 수행하면서 반환한 리스트 값을 추가하여, 각 관광지마다 상관계수 값을 가지고 온다. 다음 예에서 ‘r_list’는 코드를 수행하여 반환한 값이다. 수신한 리스트 값을 ‘r_table’ 데이터 프레임으로 만들고, 인덱스를 ‘tourpoint’로 변환한다([CODE 10] 참조).
r_list = [['창덕궁', -0.058791104060063125, 0.27744435701410114, 0.40281606330501574], ['운현궁', 0.44594488384450376, 0.3026152182879861, 0.2812576500158649], ['경복궁', 0.5256734293511214, -0.4352281861341233, 0.42513726387044926], ['창경궁', 0.4512325398089607, -0.16458589402253013, 0.6245403780269381], ['종묘', -0.5834218986767474, 0.5298702802205213, -0.12112666829294959], ['국립중앙박물관', 0.39663594900292837, -0.06923889417914424, 0.3789788348060077], ['서울역사박물관', 0.4169985898874495, 0.4929777868070643, 0.2411976107709704], ['덕수궁', 0.4332132943587757, -0.4326719125679966, 0.4808588469548069], ['서울시립미술관 본관', 0.0, 0.0, 0.0], ['태릉 · 강릉 · 조선왕릉전시관', -0.08179909096513825, 0.0634032985209752, -0.06884011648164298], ['서대문형무소역사관', 0.47262271531670347, 0.006098570233700235, 0.22900879409607508], ['서대문자연사박물관', 0.0, 0.0, 0.0], ['트릭아이미술관', 0.340084882575556, -0.15036015533747007, 0.18094502388483083], ['헌릉ㆍ인릉', -0.5813250357820897, 0.46453007122911255, -0.1853887818740637], ['선릉·정릉', -0.5715258789199192, 0.38806730592260075, -0.12494498568749024], ['롯데월드', 0.5105587922155749, 0.23511773800458452, -0.12673869767365747]]
>>> r_table = pd.DataFrame(r_list, columns=('tourpoint', 'china', 'japan', 'usa'))
>>> r_table = r_table.set_index('tourpoint')
>>> r_table
china japan usa
tourpoint
창덕궁 -0.058791 0.277444 0.402816
운현궁 0.445945 0.302615 0.281258
경복궁 0.525673 -0.435228 0.425137
창경궁 0.451233 -0.164586 0.624540
서울시립미술관 본관 0.000000 0.000000 0.000000
서대문자연사박물관 0.000000 0.000000 0.000000
…
r_table을 확인하면 ‘서울시립미술관 본관’과 ‘서대문자연사박물관’의 경우 상관계수값이 없는 것을 확인할 수 있다. 그래프에서 필요없는 열은 다음과 같이 삭제를 한다.
>>> r_table.drop('서울시립미술관 본관')
>>> r_table.drop('서대문자연사박물관')
>>> r_table = r_table.sort('china', ascending=False)
>>> r_table.head()
china japan usa
tourpoint
경복궁 0.525673 -0.435228 0.425137
롯데월드 0.510559 0.235118 -0.126739
서대문형무소역사관 0.472623 0.006099 0.229009
창경궁 0.451233 -0.164586 0.624540
운현궁 0.445945 0.302615 0.281258
해당 열의 인덱스 값을 가지고 ‘drop()’ 함수를 사용하여 데이터를 삭제한 후 ‘sort()’를 이용하여 ‘china’ 열을 내림차순으로 정렬하였다.
>>> font_location = "c:/Windows/fonts/malgun.ttf"
>>> font_name = font_manager.FontProperties(fname=font_location).get_name()
>>> matplotlib.rc('font', family=font_name)
>>> r_table.plot(kind='bar', rot=70)
<matplotlib.axes._subplots.AxesSubplot object at 0x00000082F2368BA8>
>>> plt.show()
정렬이 되었으면 그래프를 그리기 위하여 한글 폰트를 로드하고, ‘plot()’ 함수를 이용하여 그래프를 그려보면 [그림 6]과 같이 중국인 입국수 대비 관광객 입장객수의 상관계수가 높은 순서대로 3개국의 계속 비교를 할 수 있다
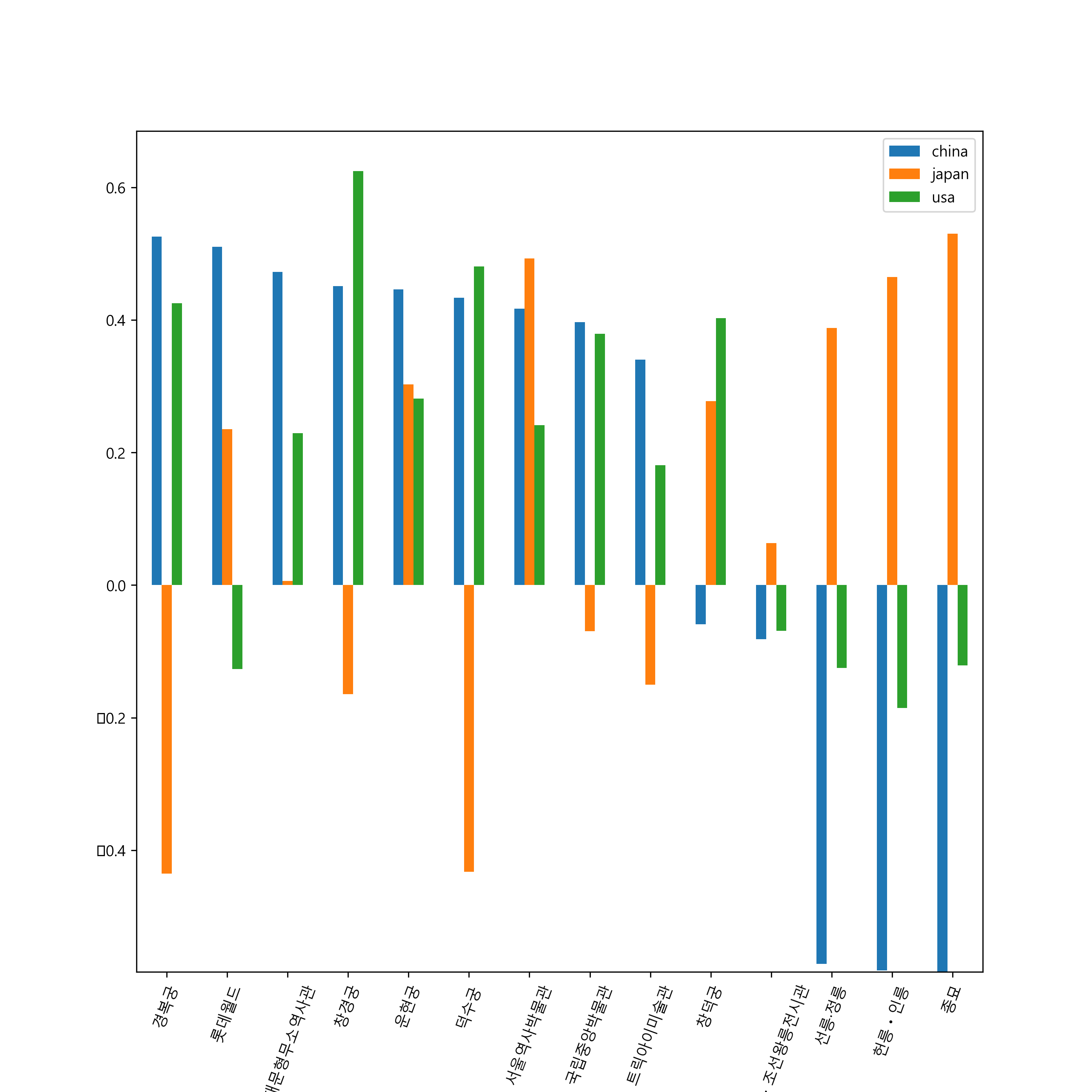 [그림 6] 중국, 일본, 미국 입국객과 서울특별시 관광지 입장객의 상관계수 분석
[그림 6] 중국, 일본, 미국 입국객과 서울특별시 관광지 입장객의 상관계수 분석
그래프를 보면 재미있는 현상이 보이는데 중국인 상관계수가 높은 관광지와 일본인 상관계수가 완전히 상반되게 나오는 관광지가 ‘경복궁’, ‘덕수궁’ ‘선릉·정릉’, 헌릉·인릉’과 ‘종묘’로 나타난다. 분석한 데이터가 6년치 관광지 입장객 통계에 불과하여 정확한 결론을 내기 힘들지만, 적어도 중국인에게 관광지를 추천한다면 ‘경복궁’, ‘롯데월드’ 순서가 될것이고 일본인에게는 ‘종묘’, ‘헌릉·인릉’순이 아닐까 생각된다(역사적 배경을 따져 보더라도 조금 의미있는 부분이 되지 않을까 생각이 들지만 정확한 결과를 도출하기 위해서는 패키지관광인지 자유관광인지, 숙박업소가 어느쪽에 편중되는지 등 영향을 미칠 요소 데이터를 확보해서 분석이 필요한 부분이다).