BIGDATA와 SNS(Social Network Service)
 [그림 1] BIGDATA와 SNS
[그림 1] BIGDATA와 SNS
최근들어 4차 산업 혁명과 인공지능(AI, 딥러닝: Deep Learning), 빅 데이터(Big Data)라는 용어는 산업계 전반에서 너무 일반적이고 유행처럼 번지고 있다. 4차 산업혁명이라는 용어는 기존의 컴퓨터 중심의 산업혁명을 벗어나 수평적, 협업적 생태계를 구축하는 조금은 새로운 패러다임이라 할 수 있지만 인공지능은 90년대 후반 한차례의 유행이 있었고 빅데이터는 데이터마이닝(Data Mining)이라는 용어로 과거부터 존재해 오고 있었다.
사실 IT 업계에 종사하는 사람들은 신조어를 만들어 내는데 익숙하다. 과거의 그룹웨어가 인터넷 환경으로 바뀌면서 동일한 기능을 수행하는 인트라넷(Intranet)으로 변모하였고 모든 기업은 인트라넷과 홈페이지를 구축하지 않으면 사업에서 도퇴되고 후진(?)기업이라고 판단, 수 많은 돈을 투자하였다. 이로 인해 많은 거대 기업이 생기고 유행이 지남과 동시에 쇄락의 길을 걸었음을 모두 기억하고 있을 것이다.
마찬가지로 인공지능과 빅데이터라는 말도 이제 유행의 정점에 올라서 있는것 같고 잠시후 죽음의 골자기(Death Valley)를 향해 달려가게 될 것이다. 물론, 이 상황에서 승리하는 플레이어는 적어도 수에서 수십년간 시장 독식을 하는 지위를 차지하게 될 것이다(아마존과 구글이 그러했던것 처럼).
과거 MIS(Management Information System) 구축 시절부터 가장 핵심적으로 이야기하던 부분이 Data와 Information의 차이이다. Data는 자체적으로 큰 의미를 가지지 못한다. 물론 하나의 값이 중요한 고장이나 중요한 의미를 가질 수 있을지 모르겠지만 데이터는 단순한 하나의 숫자 또는 자료에 불과하다. 우리는 이러한 데이터를 가공하여 정보(Information)라는 의미를 가질수 있는 데이터(?)로 가공하고 이를 사용자에게 제공하는 것이 필요하다.
정보의 특성은 영속성을 가질 수 있는것과 그렇지 않은 것으로 분리된다. 영속성을 가지는 정보란 역사적 사실과 같이 변화지 않는 것이 될 것이다. 그러나 대부분의 정보는 시간이 지나면서 무의미하거나 존재의 가치가 희석되게 된다. 특히 요즘 대세인 SNS(Social Network Service)의 경우에는 그 정보가 한시적이며 휘발성을 가지고 있다(한때 유행이었던 등갈비집은 수많은 프렌차이즈가 난립하며 유행하였지만 한순간에 사라져버렸다. 그러한 맛집 정보는 유행에 따라 정보의 가치가 올라갔지만 가계의 폐업이나 유행이 지나감으로써 무의미한 정보가 된다).
Socail Network 사용 현황
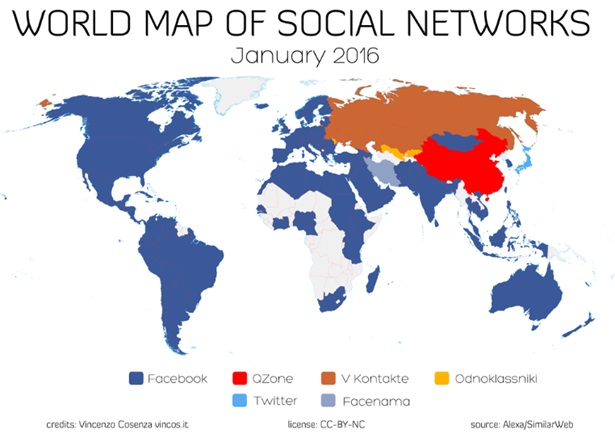 [그림 2] BIGDATA와 SNS
[그림 2] BIGDATA와 SNS
전 세계적으로 많이 사용하고 있는 SNS 프로그램은 약 5개 정도로 [그림 2]와 같이 사용자 분포를 가지고 있다. 데이터를 수집하려고 하는 지역에 따라 어떤 프로그램이 사용되고 있는지 참고하기 바란다.
Socail Data Flow
 [그림 3] SNS 데이터의 속성
[그림 3] SNS 데이터의 속성
SNS를 통하여 수집되는 데이터는 [그림 3]과 같은 속성을 가진다. 일반적으로 생성되는 데이터들은 단기(instant) 속성을 가지므로 유행이 민감한 정보등을 분석할 때 유효하게 사용할 수 있다. 또한 비슷한 경향을 가진 사람들끼리 팔로우(Follow) 하거나 좋아요(like)등을 누르게 되므로 유사성 분석을 통하여 추천(Recommendation) 서비스 등의 정보로 활용 가능하다.
데이터 수집(Crawling)과 처리
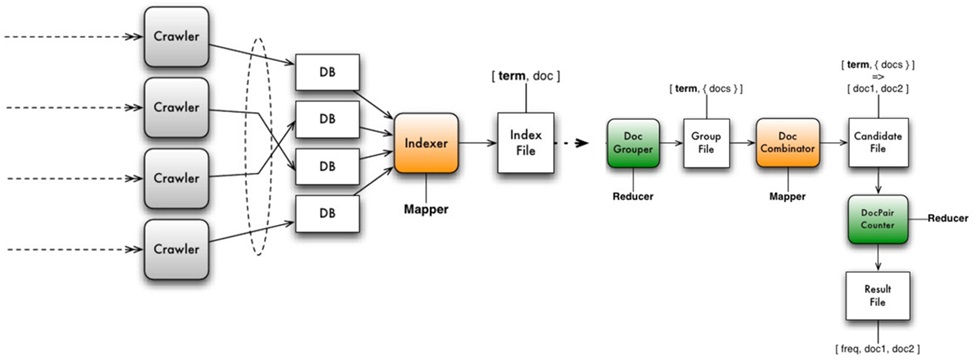 [그림 4] SNS 데이터의 수집과 처리
[그림 4] SNS 데이터의 수집과 처리
인터넷 상에 산재해있는 데이터를 수집하기 위하여 우리는 크롤러(Crawler)를 구성하게 되고, 수집한 정보는 데이터 베이스 또는 HDFS(Hadoop File System)에 저장하게 된다.
저장된 데이터는 검색의 효율성을 높이기 위하여 인덱싱(Indexing) 과정을 거치게 되고 , 이러한 데이터를 가공하여 축약된 정보DB(Mart DB)를 생성한다. 이후 이 정보를 이용하여 사용자에게 효율적으로 보여주기 위해 시각화(Visualizatino) 과정을 거쳐 인포그래픽(Infographic-정보를 포함한 그래픽)으로 최종적으로 생성해 내는 것이 빅데이터의 수집, 분석, 시각화 과정이다.
데이터 수집(Crawling) 규칙
인터넷 상에 존재하는 데이터는 누군가의 노력으로 생산되어진 저작권을 가지고 있는 자료로 취급되어야 한다. 초창기 인터넷 사용자는 “Internet is Free”라고 외치며 저작권에 대해 무관심하려는 의도를 보여왔다. 그러나 컨텐츠 생산자가 자유로운 사용을 허락하지 않는 이상 그 저작권은 생산자에게 귀속되며 우리는 이를 조심하게 사용하여야 한다.
일반적으로 저작권 법상 크롤링 또는 자료의 사용에 대해 허용하는 범위는
1) 단순 링크 : 사이트 대표 주소를 링크로 명기하고 클릭시 이동하는 형태 2) 직접 링크 : 특정 게시물을 링크하는 경우
이며 위반 사항으로는
1) 프레임 링크 : 저작물의 일부를 홈페이지에 프레임 형태로 넣어 마치 자신이 서비스하는 것처럼 보이는 행위 2) 임베드 링크 : 저잘물 전체를 홈페이에 표시하는 경우
등으로 둘 수 있다.
이러한 무분별한 인터넷 데이터의 사용을 금지하기 위하여 웹 규약에서는 해당 사이트의 크롤링 범위를 정의하는 “robots.txt” 파일을 서비스 웹 서비스의 root에 저장하도록 되어 있다(안타깝게도 많은 웹 개발자나 웹 디자이너가 robots.txt 파일이라는 것이 존재하는 지 모르고 있는것이 현실이다 -.-;;). 다음의 표는 robots.txt의 사용예를 나타낸다.
| Site | Status |
|---|---|
| 모두 허용 | User-agent:* Allow: / |
| 모두 차단 | User-agent:* Disallow: / |
| 다른 예 | User-agent: googlebot #googlebot 크롤러만 적용 Disallow: /bbs/ #/bbs 디렉터리 접근 차단 |
실 예로 http://www.naver.com/robots.txt 에 웹 브리우저를 이용하여 접근해 보면 네이버의 크롤러 접근 규칙에 대해 확인이 가능하다.
SNS API(Application Programming Interface)
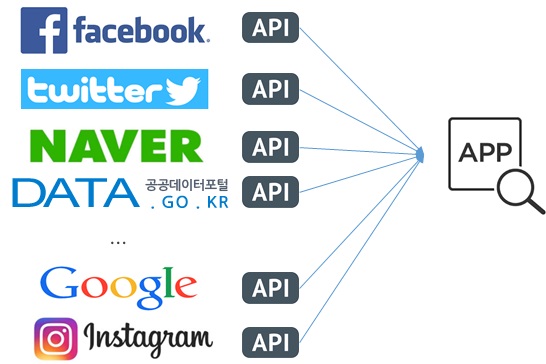 [그림 5] SNS API
[그림 5] SNS API
인터넷 환경이 급속하게 발전하면서 이제는 개인이 데이터를 만들어 내고 이를 공유하는 것이 보편화된 세상에 살고 있다. 이러한 기술의 발전중에 SaaS(Software as a Service)라는 용어가 있다. SaaS는 소프트웨어 및 관련 데이터가 중앙에 위치하고 사용자는 웹 브라우저등을 이용하여 접속하여 소프트웨어를 사용하는 서비스 모델을 이야기한다.
페이스북이나 트위터는 자신들이 서비스하는 여러 가지 기능을 SaaS의 개념으로 다른 사용자들이 활용할 수 있는 API(Application Programming Interface)를 제공해 준다. 우리는 이러한 API를 이용하여 SNS의 내용을 읽어 오거나, 다양한 형태의 데이터를 제공받을 수 있다. 과거에는 웹 페이지 또는 서비스의 내용을 가지고 오기 위하여 크롤러(Crawler)라는 것을 만들고 URL에 접근하여 데이터를 가지고 왔어야 하는데 이러한 수고를 덜어주고 간단하게 데이터를 가지고 올 수 있는 서비스를 제공한다.